

What Is Encoder And Decoder: AI & Beyond
You’ve probably used a translation app, dictated a message, or asked a chatbot to rewrite something and gotten a polished result in seconds. The output feels smooth, but the machinery behind it can sound oddly technical. Terms like encoder, decoder, embedding, and attention often make a simple idea seem harder than it is.
It doesn’t have to be that way.
The easiest way to understand what is encoder and decoder is to follow one consistent story: a translator hears a sentence, understands its meaning, then expresses that meaning in a new form. That same pattern shows up in old-school digital logic, speech systems, image tools, and modern AI models.
Your Guide to AI's Secret Superheroes
You tap the microphone on your phone, say a sentence, and watch text appear almost instantly. Or you paste a line into a translator and get a clean version back in another language. That result feels simple because the hard part happens in the middle.
AI usually solves this by splitting the job in two.
An encoder takes the raw input, such as speech, text, or an image, and turns it into a compact internal representation. A decoder takes that representation and produces the output, such as words on a screen, a translated sentence, or a caption. Using the translator thread, the encoder is the part that understands the message, and the decoder is the part that expresses that understanding in a new form.
That pattern shows up in more places than many beginners expect.
It helps explain why machine translation works, how a speech system turns sound into language, and how a model can look at an image and describe what is in it. The same basic idea also appears outside modern deep learning, including classic electronics, where encoders and decoders map one form of input to another in very specific ways.
The useful mental shift is this: an encoder and decoder are not random AI jargon. They describe a division of labor. One part reads and condenses meaning. The other part rebuilds that meaning into the form you need.
Once that clicks, terms that sound intimidating start to feel much more ordinary.
If you’re building your AI foundation and want a broader learning path around practical concepts, courses, and tools, you might also [discover Masteringai](https://www.saaspa.ge/user/ masteringai) as a useful companion resource.
The Core Idea Explained with a Simple Analogy
A human translator is the best starting point.
Suppose someone says, “Hello, how are you?” in English. A skilled translator doesn’t usually do a crude word-for-word swap. They first understand the meaning, tone, and intent. Only after that do they produce the equivalent sentence in French, Japanese, or another language.
That two-step process is the heart of encoding and decoding.
The translator mental model
Encoding is the understanding phase. The translator hears the sentence and forms an internal concept of what it means.
Decoding is the expression phase. The translator takes that internal concept and produces a new sentence in the target language.
The key point is the middle step. The system doesn’t jump directly from one surface form to another. It creates an internal representation first.
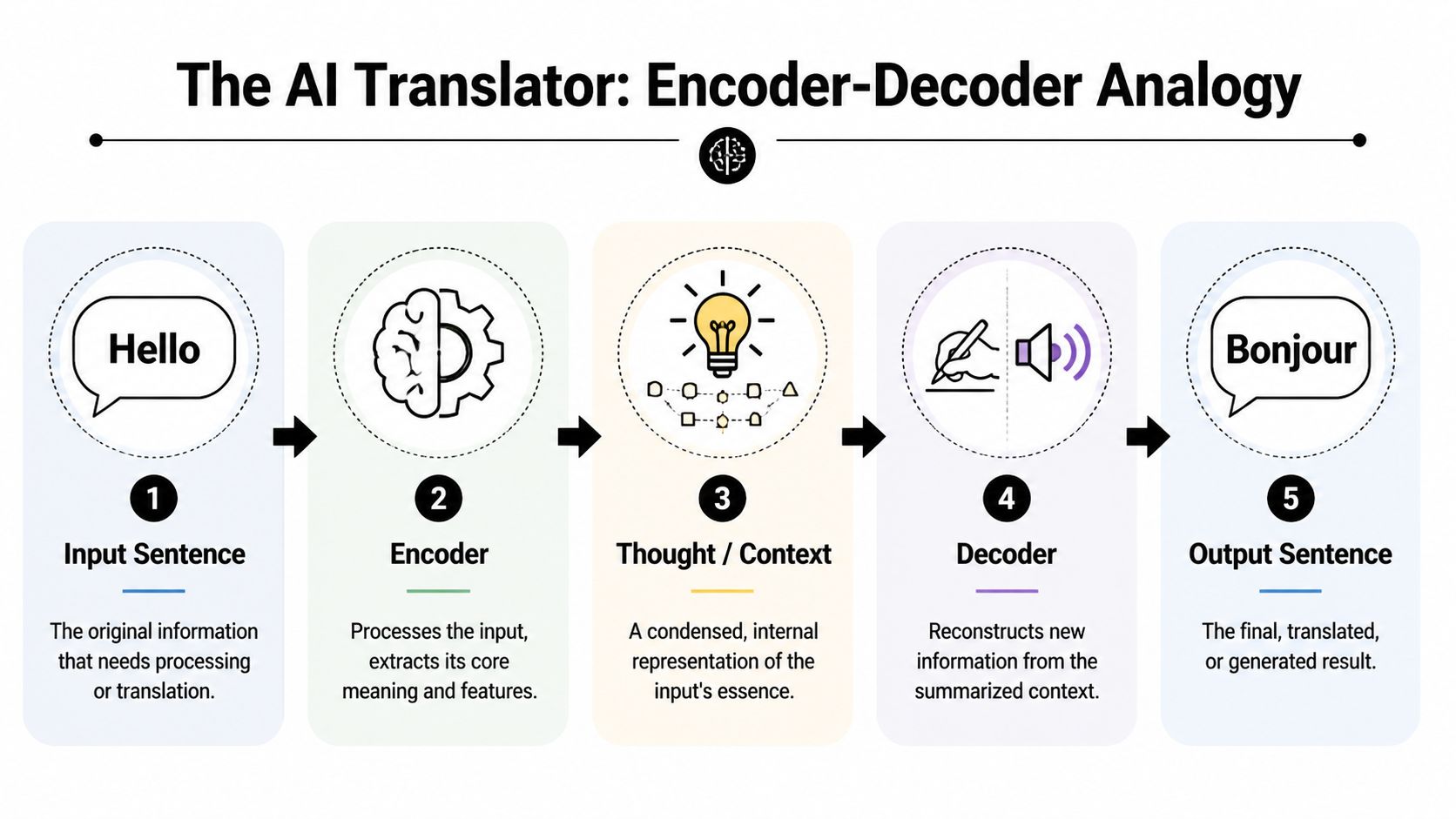
That middle representation could be thought of as a compact “idea” of the input. In AI, that idea is usually represented as numbers. In a human, it’s understanding. In both cases, the pattern is the same.
The same idea in electronics
This isn’t only an AI concept. Digital logic has used encoders and decoders for a long time.
In traditional digital logic systems, an encoder accepts 2^n input lines and produces n output lines, while a decoder performs the reverse. Encoders typically use OR gates as their basic logic element, while decoders use AND gates or NAND gates combined with NOT gates for more complex decoding operations, as explained in this digital logic breakdown from GeeksforGeeks.
A simple example helps:
- Decimal-to-binary encoding: one active input line representing a digit gets converted into a compact binary code.
- Binary decoding: that compact code gets turned back into the correct output line.
- Communication flow: encoders sit at the sending side, decoders at the receiving side.
So even outside AI, the broad pattern is familiar:
- Take something detailed or spread out.
- convert it into a more useful code,
- then reconstruct or route it correctly on the other side.
Practical rule: If you’re confused, ask one question. “What is being turned into what?” That usually reveals which part is the encoder and which part is the decoder.
How AI Uses Encoders and Decoders
In AI, the same translator pattern becomes much more powerful.
An AI encoder can take a paragraph, an image, or an audio clip and turn it into a mathematical representation. That representation is often called an embedding or vector. You can think of it as the model’s internal summary of the important features in the input.

What the encoder actually does
The encoder doesn’t just “shrink” data. Its real job is to create a representation that preserves meaning and relationships.
For text, that might include:
- Word relationships: whether words relate to time, place, sentiment, or action
- Context: whether “bank” means a riverbank or a financial institution
- Structure: how different parts of the sentence depend on each other
For images, it might capture shapes, objects, textures, and spatial relationships. For audio, it might capture phonemes, timing, and patterns in the waveform.
What the decoder does with that representation
The decoder takes the internal representation and generates something useful:
- a translated sentence
- an image caption
- a speech transcript
- a summary
- a response in a chat system
This is why the encoder-decoder setup is so common in tasks where input and output are different in form or structure. A picture becomes a sentence. Speech becomes text. One language becomes another.
If you’re also trying to explain technical ideas clearly for teammates or clients, this guide to turning ideas into polished decks is a practical resource because encoder-decoder ideas often make more sense once you visualize the flow.
Why this matters for language models
Many newcomers hear about GPT first and assume all AI language systems work the same way. They don’t. Some models are designed mainly for generation, while others are designed to understand and transform inputs more deliberately.
If you want the bigger picture around modern text models, this overview of large language models helps place encoders and decoders in the broader ecosystem.
A quick visual can help if you like seeing the concept in motion:
A good encoding is less like zipping a file and more like capturing the meaning that a downstream task will need.
A Closer Look at Famous AI Architectures
Once the basic pattern clicks, a lot of famous AI architectures start to look much less mysterious. They all reuse the same idea in different ways.
Autoencoders
Autoencoders are the most stripped-down version.
They take an input, pass it through an encoder into a compact internal representation, then use a decoder to reconstruct the original input. The model learns by getting better at reconstruction.

People often use autoencoders for tasks like:
- Denoising images: remove visual noise while preserving the underlying structure
- Compression-style representation learning: keep the important features, drop the clutter
- Feature extraction: learn useful internal summaries for later tasks
The interesting part is that the model teaches itself what matters by trying to rebuild the input from a bottleneck.
Sequence-to-sequence models
Classic translation systems often used a sequence-to-sequence, or Seq2Seq, design.
The encoder reads the input sequence. The decoder then generates the output sequence one piece at a time. This pattern became central for machine translation and summarization because input and output lengths often differ.
A short English sentence can become a longer German one. A long article can become a short summary. Encoder-decoder models are naturally suited to that mismatch.
Transformers
Transformers took the encoder-decoder idea and made it far more flexible.
Encoder-decoder architectures are now one of the foundational shifts in neural network design since the original transformer architecture, and they’ve evolved into encoder-only, decoder-only, and encoder-decoder hybrid families, with common applications in machine translation, summarization, image captioning, and speech recognition, as described in Sebastian Raschka’s explanation of encoders and decoders in transformer systems.
The part many readers get stuck on is attention.
Why attention changed everything
In a Transformer’s decoder, there are three distinct parts: a self-attention layer, a feed-forward neural network, and an encoder-decoder attention layer. That encoder-decoder attention lets the decoder focus on specific parts of the encoder’s output while generating each output token, as explained in this transformer decoder walkthrough.
Here’s the beginner version:
| Model type | Best mental model | Typical use |
|---|---|---|
| Autoencoder | Compress and reconstruct | Denoising, representation learning |
| Seq2Seq | Read one sequence, write another | Translation, summarization |
| Transformer | Read, attend, and generate with flexible context | Modern NLP and multimodal tasks |
Instead of relying on one fixed summary, the decoder can keep checking relevant parts of the input. That’s a lot like a translator glancing back at the source sentence while writing.
Attention gave the decoder a better memory of the source. That’s why transformer-based systems handle complex mappings far better than older designs.
A Simple Autoencoder in Python Code
A small code example makes the idea less abstract. Here’s a minimal dense autoencoder in Keras for image-like data with 784 input values and a 32-value encoded representation.
The code
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Input layer: 784 values, like a flattened 28x28 image
input_img = keras.Input(shape=(784,))
# Encoder: compress the input into a smaller representation
encoded = layers.Dense(32, activation="relu", name="encoded_layer")(input_img)
# Decoder: reconstruct the original 784-value input
decoded = layers.Dense(784, activation="sigmoid", name="decoded_layer")(encoded)
# Full autoencoder model
autoencoder = keras.Model(input_img, decoded, name="autoencoder")
# Separate encoder model
encoder = keras.Model(input_img, encoded, name="encoder")
# Build a separate decoder model
encoded_input = keras.Input(shape=(32,))
decoder_layer = autoencoder.get_layer("decoded_layer")
decoder = keras.Model(encoded_input, decoder_layer(encoded_input), name="decoder")
# Compile the full model
autoencoder.compile(optimizer="adam", loss="binary_crossentropy")
# View the architecture
autoencoder.summary()
encoder.summary()
decoder.summary()
How to read it
The first dense layer is the encoder. It takes the 784-value input and turns it into 32 numbers. That 32-number vector is the bottleneck, or compressed internal representation.
The second dense layer is the decoder. It takes those 32 numbers and tries to rebuild the original 784 values.
Why this matters
Even if you never train this exact model, the structure is the lesson:
- Input goes in
- encoder creates a compact representation
- decoder reconstructs output from that representation
That’s the pattern behind much more advanced systems too. The fundamental difference in larger models is scale, architecture, and training method.
If you want to go from this toy example to actual training workflows, this guide on how to train a neural network is a useful next step.
Choosing Your Model When to Use Encoder-Decoders
Once you understand the architecture, the next practical question is simple. When should you choose an encoder-decoder model instead of a decoder-only one?
For business teams and developers, this isn’t academic. It affects cost, latency, and output quality.

The short decision rule
Use encoder-decoder models when the task is mainly a transformation task. Translation, summarization, speech-to-text, and image-to-text all fit this pattern because the system has to understand one structure and produce another.
Use decoder-only models when the task is mostly continuation or open-ended generation. Chat, drafting, and code generation often fit better there.
That’s the broad rule. The trade-off is where things get real.
Cost and quality trade-offs
A 2024 Slator analysis of AI translation benchmarks found that encoder-decoder models outperformed decoder-only models by up to 15% in contextual fidelity and quality across 10 language pairs, but at 1.5 to 2x higher inference costs due to dual components, according to the comparison summarized in this encoder-decoder discussion.
So the choice often comes down to this table:
| If your priority is… | Better fit |
|---|---|
| Precise input-to-output transformation | Encoder-decoder |
| Fast generation-heavy workflows | Decoder-only |
| Clear structural mismatch between input and output | Encoder-decoder |
| Single-stream text continuation | Decoder-only |
Why encoder-decoders are still relevant
A lot of beginner content implies that decoder-only models have “won.” That’s too simplistic.
There’s an important concept called mismatch. In plain English, it means the system’s internal compression can lose structure that matters later. That becomes especially important in multimodal systems, where the model has to connect different kinds of information such as images and text.
Recent hybrid encoder-decoder integrations in 2025 multimodal models showed 20% gains in cross-modal alignment, according to Hugging Face benchmarks cited in IBM’s overview of encoder-decoder models and multimodal AI.
That matters because some tasks punish sloppy understanding. In healthcare, document-heavy workflows, and safety-critical systems, a model that separates understanding from generation can be the smarter choice even when it costs more.
Expert view: If the output must faithfully reflect a complex input, I’d lean toward an encoder-decoder design before I reached for a decoder-only model.
Frequently Asked Questions About Encoders and Decoders
Can you use just an encoder or just a decoder
Yes, and that helps clear up a common beginner confusion.
A translator does not always need to do both jobs. Sometimes the task is only to read and understand a sentence. Other times the task is only to produce fluent text from a prompt. AI models work in a similar way.
Encoder-only models are built for understanding the input well. They are often used for classification, tagging, search, and retrieval.
Decoder-only models are built for generating the next output step by step. They are often used for chat, drafting, and text continuation.
Encoder-decoder models do both. One part reads and organizes the input, and the other part turns that understanding into a new output.
So yes, all three patterns are common. The right one depends on whether your task is mostly understanding, mostly generation, or a translation from one form to another.
Do encoders always compress data
Encoders compress meaning more often than they compress size.
That distinction matters. In the translator thread we have used throughout this article, the encoder is like the stage where the translator reads a paragraph and forms a clear internal summary of what matters. That summary may be shorter than the original wording, but the goal is not shrinking data. The goal is keeping the parts the next step needs.
In neural networks, that internal representation is often called a latent representation or embedding. It may be smaller, denser, or reorganized into a form the model can use more effectively.
A tiny representation can still be poor if it drops important details. A larger one can be useful if it preserves the structure the decoder needs to produce a good result.
Are encoders and decoders a new AI invention
No. The basic pattern is much older than modern deep learning.
Engineers have used encode-and-decode systems in communications, compression, and signal processing for decades. What changed in AI is the kind of information being handled. Instead of converting a simple signal into another fixed format, neural networks learn how to represent language, images, audio, and other complex data in a way that supports a task.
That is why the same core idea shows up in very different places. A simple autoencoder can learn to reconstruct an input. A translation model can turn one language into another. A vision-language system can read an image and produce text. The underlying rhythm stays familiar. First understand the input. Then generate the output.
If you want practical, readable explanations of AI concepts without the usual jargon overload, YourAI2Day is a solid place to keep learning. It’s especially useful if you’re trying to connect core ideas like encoders and decoders to real tools, business decisions, and fast-moving AI trends.




