

What is a Neural Network? A Beginner’s Guide to AI
Ever wonder how your phone unlocks the instant it sees your face? Or how Netflix seems to know exactly what movie you’re in the mood for? The magic behind the curtain is usually a neural network. At its core, a neural network is a computing system designed to learn in a way that’s inspired by the human brain. Instead of following a rigid set of pre-programmed rules, it sifts through data, finds patterns, and makes decisions, getting smarter over time.
The Big Idea Behind Neural Networks
Think of a neural network as a digital brain you can teach to master a specific task, all without needing a step-by-step instruction manual. It’s the technology that powers many of the "smart" features you use every single day.
While it feels like a recent breakthrough, the core idea has been around for quite a while. The journey started back in 1943 when Warren McCulloch and Walter Pitts developed the first simple computational model of a neuron. Things really got moving with Frank Rosenblatt's perceptron in 1958—the first tangible neural network built to handle basic classification tasks. You can take a deeper dive into the history and evolution of AI on Codewave.com.
Learning Like a Human (Almost)
So, how does a machine actually "learn"? Let’s break it down with a friendly analogy.
Imagine you're teaching a toddler to recognize a cat. You wouldn't give them a list of logical rules, like "if the animal has pointy ears, whiskers, and a long tail, then it is a cat." That's not how we learn. Instead, you'd show them lots of pictures of different cats—fluffy ones, skinny ones, striped ones, and so on.
A neural network follows a strikingly similar process:
- It sees examples: You feed the network thousands of images, some labeled "cat" and others labeled "not a cat."
- It makes a guess: For each new image, it tries to predict whether it’s a cat. At first, these guesses are wild and almost always wrong.
- It gets feedback: After each guess, the network is told if it was right or wrong. This feedback is crucial; it’s the signal to make an adjustment.
- It gets smarter over time: This cycle of guessing, checking, and adjusting is repeated millions of times. Slowly but surely, the network starts to fine-tune its internal connections, learning to associate features like pointy ears, fur, and certain eye shapes with the "cat" label.
Expert Opinion: As Andrew Ng, a pioneer in the field, often puts it, the magic of neural networks is that they learn features automatically. "The beautiful thing about neural networks is that they aren't programmed; they are trained. You show them what you want, and they figure out the 'how' on their own. This ability to learn from data is what allows them to solve problems that are incredibly difficult to code by hand, from understanding human speech to detecting diseases."
This simple yet powerful loop—guess, get feedback, adjust—is what allows neural networks to solve incredibly complex problems that would be nearly impossible for a human to program with traditional code.
How a Neural Network Actually Learns
Okay, we've got the big picture. But how does the learning really happen inside the machine? It’s not magic, but rather a clever, iterative process of trial and error, almost like a game of "hot or cold."
Let's use a practical example: an email spam filter. Imagine the neural network is a team of rookie detectives trying to spot fraudulent emails.
The first layer of detectives gets the raw evidence—the words and symbols in the email. Each detective (a neuron) has a very specific job. One looks for the word "free," another for "winner," and a third for an excessive number of exclamation points. They don't solve the case on their own; they just pass their initial findings up the chain of command.
Deeper in the agency, the next layer of detectives starts putting these clues together. One might notice that the "free" detective and the "exclamation point" detective are both sounding the alarm. That combination seems suspicious, so this detective passes a stronger "likely spam" signal to their boss. This process continues until the final detective makes the call: "This is spam."
This simple loop—input, guess, and check—is the absolute core of how a network gets smarter over time.
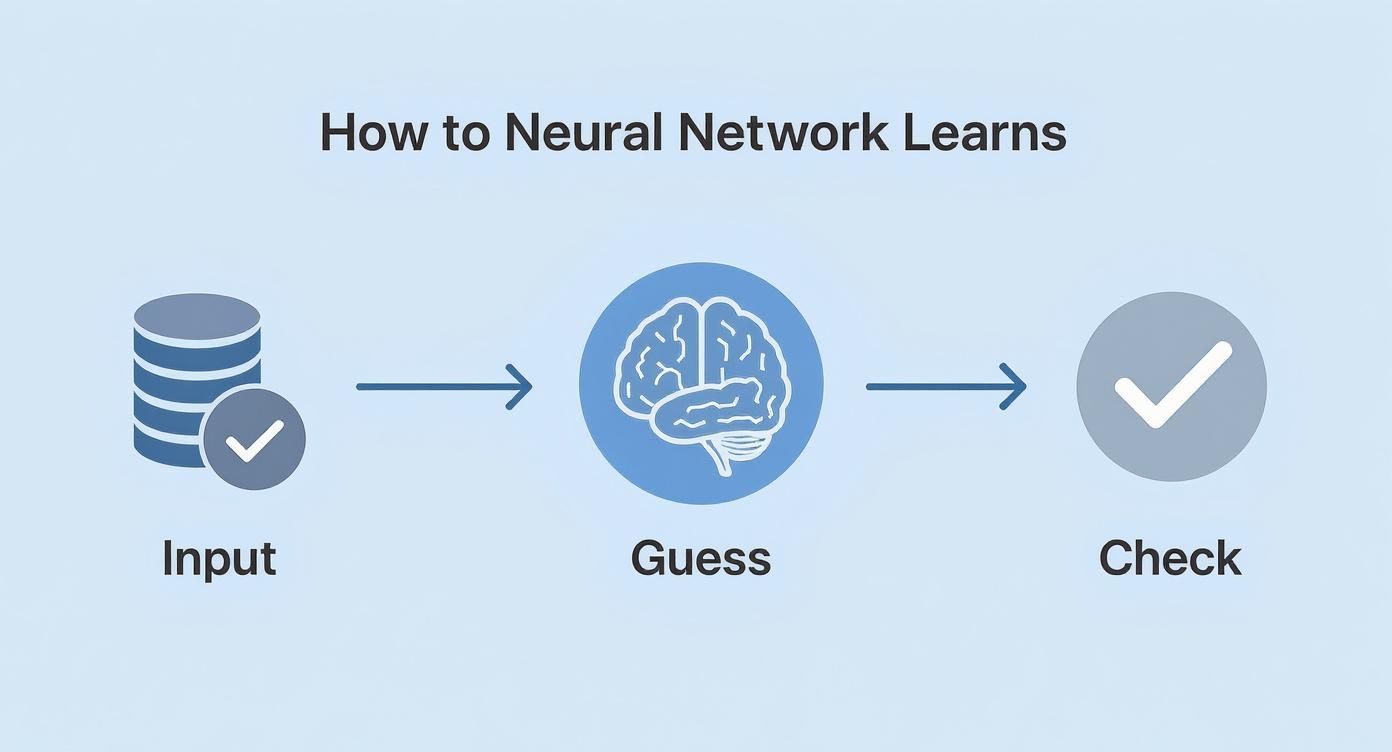
Learning isn't a one-and-done event. It's a continuous cycle of making a prediction, seeing how wrong it was, and using that mistake to make a slightly better prediction next time.
The Tuning Knobs of Learning
So, what happens when the network gets it wrong? How does it adjust its thinking? This is where a few key components come into play. Think of them as tiny tuning knobs that the network can tweak with every single example it sees.
Here are the three most important players:
- Weights: In our detective agency, a weight is the amount of credibility given to each detective's report. At first, the network might treat every clue equally. But after seeing thousands of emails, it learns that the word "invoice" from a known contact is a weak signal for spam, while "winner!" is a very strong one. It adjusts the weights to reflect this, effectively telling itself which clues to pay more attention to.
- Biases: A bias is like a detective's gut feeling. One might be naturally skeptical and lean toward marking things as spam unless proven otherwise. A bias gives a neuron a starting point, making it more or less likely to fire before even looking at the evidence.
- Activation Functions: This is the final decision rule for each neuron. After weighing the evidence (inputs multiplied by their weights) and factoring in its bias, the neuron needs to decide how loudly to shout its conclusion. The activation function translates this combined signal into a clean output, often a number between 0 and 1. A score of 0.9 might mean "I'm almost certain this is spam," while 0.1 means "I really don't think so." If you want to dive deeper, you can learn all about the role of an activation function in a neural network in our detailed guide.
These three pieces—weights, biases, and activation functions—all work in concert. The network makes a guess, checks the answer, and if it was wrong, it nudges all the little knobs across the entire detective agency to get closer to the right answer next time.
The real magic here is that the network isn't just memorizing a list of spam words. It's learning the relationships and patterns between words and phrases. It's a level of nuanced understanding that would be practically impossible for a human to program by hand.
Our Spam Detector in Action
Let's walk through one single learning cycle.
- Input: We give the network an email with the subject "You're a winner!" The network first breaks this down into a numerical format it can work with.
- Forward Pass (The Guess): The data flows through the layers. The first-layer neurons fire up in response to "winner" and the exclamation mark. This signal is passed on, and neurons in the next layer recognize this combination as a huge red flag. The final neuron spits out a high value, say 0.95, which is its guess for "This is spam."
- Calculate the Error (The Check): This is the moment of truth. For this training example, we already have the correct label: it is spam (which we'll represent as a 1). The network guessed 0.95. The gap between the right answer (1) and the guess (0.95) is 0.05. This gap is called the loss or error.
- Backpropagation (The Correction): The network now sends this error signal backward through the layers. It essentially tells each neuron how much it contributed to the mistake. The neurons that confidently and incorrectly voted "not spam" get a bigger "correction" than those that were already leaning the right way.
- Update Weights and Biases: Using these correction signals, the network makes tiny adjustments to its tuning knobs. The weight for the connection that spotted "winner!" gets a small boost, making it even more influential on the next guess.
This entire process, from input to update, is repeated millions of times with different emails. With every cycle, the network’s internal configuration gets a little bit better, and its ability to separate junk from legitimate mail becomes sharper and more reliable. It's not memorizing—it's building an intuition from raw data.
Exploring Different Types of Neural Networks
Not all problems are the same, and neither are all neural networks. Think of it like a carpenter's toolbox: you wouldn't use a hammer to cut a piece of wood. In the world of AI, developers have created specialized network architectures, each one uniquely suited for a particular kind of job.
Just as a team of specialists brings different skills to a project, these networks are designed to excel at specific tasks like seeing, hearing, or understanding language. Let's meet a few of the all-stars you'll encounter most often.

Convolutional Neural Networks (CNNs): The Vision Experts
Have you ever wondered how your phone’s camera can detect faces in a photo or how a self-driving car identifies pedestrians? The hero behind these visual feats is the Convolutional Neural Network (CNN). These networks are the undisputed champions of processing visual information.
A CNN works a lot like how our own eyes process a scene. Imagine you're trying to find a specific shape in a large, detailed painting. You might take a small magnifying glass and scan it across the canvas, section by section. A CNN does something remarkably similar. It uses digital filters, or "kernels," that slide over an image to detect specific features.
The process is brilliantly layered:
- Early Layers: The first filters might only spot simple things like edges, corners, or patches of color.
- Middle Layers: These layers then take the findings from the earlier ones and combine them into more complex shapes—an eye, a nose, or a wheel.
- Final Layers: Finally, the network pieces all these complex features together to make a high-level judgment: "This is a cat," or "That is a stop sign."
This layered approach to feature detection makes CNNs incredibly effective for any task involving grids of data, especially images. It’s why AI can now analyze medical scans for signs of disease with impressive accuracy.
Recurrent Neural Networks (RNNs): The Sequence Specialists
What about tasks that involve order and time, like understanding a sentence or predicting the next word you’ll type? For these, we turn to Recurrent Neural Networks (RNNs). Their unique superpower is memory.
Unlike other networks that treat every input as a brand new event, an RNN has a feedback loop. This loop allows information from previous steps to stick around and influence the current one. It’s a lot like reading a book. You don't just understand each word in isolation; your comprehension of the current word depends heavily on the words that came before it.
An RNN operates on this exact principle. It maintains a 'hidden state,' which is like a running summary of everything it has seen in the sequence so far. This memory is what allows it to grasp context and make sense of sequential data.
This ability makes RNNs a natural fit for:
- Natural Language Processing (NLP): Powering chatbots, translation services, and text summarization tools.
- Speech Recognition: Converting your spoken words into text by understanding the sequence of sounds.
- Time-Series Prediction: Forecasting stock prices or weather patterns based on historical data.
However, traditional RNNs can struggle with long-term memory. They sometimes "forget" important information from early in a sequence. This led to more advanced versions like LSTMs (Long Short-Term Memory networks), which have special mechanisms to help them remember important context over longer periods.
Transformers: The Modern Language Masters
While RNNs were the go-to for language for a long time, a newer architecture has completely taken over the spotlight: the Transformer. Introduced in 2017, this design powers nearly all of the advanced AI you hear about today, including models like ChatGPT.
The key innovation here is a mechanism called attention. If an RNN reads a sentence one word at a time, a Transformer can look at all the words in the sentence simultaneously. The attention mechanism allows the model to weigh the importance of every other word when processing a specific one.
For example, in the sentence "The robot picked up the red ball because it was heavy," the model needs to know that "it" refers to the "ball," not the "robot." Attention is what allows the network to make these crucial connections, no matter how far apart the words are. This parallel processing and superior context management have made Transformers exceptionally powerful.
Here's a quick cheat sheet to help you keep these powerful architectures straight.
Common Neural Network Architectures Compared
| Network Type | What It's Good At (Its Superpower) | Common Real-World Example |
|---|---|---|
| Convolutional Neural Network (CNN) | Processing grid-like data, like images. It's an expert at finding patterns and features. | Your phone's camera identifying faces in a photo. |
| Recurrent Neural Network (RNN) | Understanding sequences and time. It has a 'memory' of what came before. | The autocomplete feature that suggests the next word as you type. |
| Transformer | Grasping complex context in language by looking at all words at once. | Advanced chatbots like ChatGPT understanding and generating human-like text. |
As you can see, each design represents a different approach to problem-solving. While these are some of the most common, the field is always growing. For a deeper dive into these and other structures, check out our guide on the different types of neural network architecture. Understanding these core types gives you a fantastic foundation for appreciating how AI solves such a wide array of human challenges.
Seeing Neural Networks in Your Everyday Life
The term "neural network" might sound like something confined to a high-tech research lab, but you're probably interacting with dozens of them before you even finish your morning coffee. This isn't some futuristic idea; it's the invisible machinery running a huge part of your digital life, from your entertainment to your security.
Once you see how these networks operate in the wild, the abstract concepts start to click. Let's look at a few examples you definitely use every day.

Your Personalized Entertainment Curator
Ever wonder how Netflix just knows what you want to watch next? That uncanny ability to suggest the perfect show isn't magic—it's a massive recommendation engine built on neural networks.
These systems sift through mountains of data to find hidden connections:
- What you watch: Every show you binge, movie you finish, or trailer you skip.
- How you interact: The thumbs-up you give, the things you add to your list.
- What people like you watch: It finds users with similar tastes and learns from their behavior. For instance, it might notice that people who love Stranger Things also tend to enjoy The Witcher, even though they are in different genres.
By spotting incredibly subtle patterns across millions of people, the network gets exceptionally good at predicting what will keep you hooked. This is a classic example of a system learning complex relationships that a human could never program with simple "if-then" rules.
The Magic of Instant Recognition
Think about your phone’s face unlock feature. That split-second recognition is a Convolutional Neural Network (CNN)—the vision specialist we talked about earlier—doing its job.
When you first set it up, the CNN analyzes your face and breaks it down into a unique mathematical signature. It’s not just saving a picture; it’s learning the precise geometry of your features, like the distance between your eyes and the curve of your jaw. Every time you unlock your phone, it compares the live camera feed to that signature. It's so robust it can still recognize you with glasses, in bad lighting, or with a new haircut.
Understanding Your Voice Commands
Whenever you talk to Siri, Alexa, or Google Assistant, you're tapping into a chain of sophisticated neural networks built for language.
First, your speech is turned into text. This is often handled by models like Recurrent Neural Networks (RNNs) or more modern variants, which are trained on thousands of hours of speech to master the patterns of human sound.
But that's just step one. Once your request is in text form—say, "What's the weather like in Austin tomorrow?"—a Transformer model often steps in to figure out what you actually mean. It analyzes the sequence of words to grasp the intent behind your command, allowing it to give you a genuinely helpful answer instead of just a keyword match.
These consumer gadgets are just the most visible part of a much larger trend. Neural networks are the engine driving a massive, fast-growing AI industry. The global AI market was valued at USD 136.55 billion in 2022 and is projected to skyrocket. From stopping bank fraud to helping doctors analyze medical scans, these models are becoming fundamental to how the world works. You can read more about the extensive impact of neural networks to see just how deep it goes.
The Power and Pitfalls of This Technology
https://www.youtube.com/embed/chfj7RHA5vM
To really get a handle on neural networks, you need to see both sides of the coin. These systems are incredibly powerful and have cracked problems we once thought were unsolvable. But they also come with some serious limitations and risks you can't ignore.
The real magic of a neural network is its uncanny ability to find patterns in massive, messy piles of data. Think about problems that are just too fuzzy for traditional code—that's where these networks shine. This capability was famously put on display back in 2012 by a model called AlexNet, which completely upended the world of computer vision.
Competing in the big ImageNet challenge, AlexNet achieved a top-5 error rate of just 15.3%. That number might not sound thrilling on its own, but the next-best competitor was stuck at 26.2%. This wasn't just a small step forward; it was a giant leap that proved deep learning could deliver on its promises and essentially kicked off the modern AI boom. You can read more about this game-changing deep learning breakthrough and how it all went down.
But that kind of power doesn't come for free. There are some major strings attached.
Common Challenges and Limitations
For all their strengths, neural networks are far from a silver bullet. If you're just starting out, it's worth knowing about a few common headaches that even the pros deal with every day.
-
The "Black Box" Problem: A network can give you a stunningly accurate answer, but it often can't tell you how it got there. This lack of transparency is a huge deal-breaker in high-stakes fields like medicine or finance, where the "why" can be just as important as the "what."
-
A Massive Appetite for Data: Most networks need to be fed enormous amounts of labeled data to learn well. Finding, cleaning, and labeling all that data can be a monstrously expensive and time-consuming job, putting it out of reach for smaller teams or specialized problems.
-
The Risk of Inherited Bias: This is probably the biggest and most dangerous pitfall. A neural network only knows what you show it. If the data you feed it is packed with real-world human biases, the AI will learn them—and often make them even worse.
Expert Opinion: Dr. Timnit Gebru, a leading researcher in AI ethics, highlights this perfectly. "An AI model is a mirror reflecting the data it was trained on. If that data contains societal biases related to race, gender, or age, the model will inevitably produce biased and unfair outcomes. The danger is that we often mistake the model's output for objective truth."
Imagine you're building an AI to screen résumés. You train it on hiring data from a company that, for decades, mostly hired men for its engineering jobs. The network will quickly learn to associate male candidates with success, automatically penalizing equally qualified women.
It’s not acting out of malice; it’s just dutifully replicating the patterns it was taught. This is why the people building these systems have a massive responsibility to find and use data that’s as fair and representative as possible.
Common Questions About Neural Networks
As you dive into the world of AI, it’s natural for a few questions to pop up. The concepts can seem a bit abstract at first, so let's walk through some of the most common ones. My goal here is to clear up any confusion and help you get a more solid footing.
Do I Need to Be a Math Genius to Understand This?
This is, by far, the most common fear I hear. The short answer is no, absolutely not.
It's true that the deep inner workings of a neural network are built on some heavy-duty math like calculus and linear algebra. But you don't need to be an expert in them to get a fantastic grasp of the core ideas.
Think of it like driving a car. You don’t need to be a mechanical engineer who can blueprint an internal combustion engine just to drive to the store. You just need to know how the steering wheel, pedals, and road rules work.
In the same way, understanding what a neural network is and what it can do is about the high-level concepts and analogies, not memorizing formulas. You can get a deep, practical understanding by focusing on the what and the why, not just the mathematical how.
What’s the Real Difference Between AI, Machine Learning, and Deep Learning?
These terms get thrown around interchangeably all the time, which is incredibly confusing when you're starting out. The easiest way I've found to explain it is to picture a set of Russian nesting dolls.
-
Artificial Intelligence (AI): This is the biggest doll, the all-encompassing idea. AI is the broad field of creating machines that can do things we'd normally associate with human intelligence—things like reasoning, learning, and solving problems.
-
Machine Learning (ML): This is the next doll inside. ML is a specific approach to achieving AI. Instead of hand-coding a million rules, you give the machine a bunch of examples and let it figure out the patterns on its own. It learns from data.
-
Deep Learning: This is the smallest doll, right in the center. Deep learning is a specialized type of machine learning that uses multi-layered neural networks (that’s where the "deep" comes from). This is the engine behind most of the big AI breakthroughs you see in the news today.
So, all deep learning is machine learning, and all machine learning is AI. But not all AI uses machine learning—some older systems were just based on a giant list of hand-coded "if-then" rules.
How Can Someone Start Learning to Build a Neural Network?
Getting your hands dirty is more doable today than ever before, thanks to some incredible open-source tools and welcoming communities. You don't have to start from scratch, reinventing the wheel with complex math. You get to stand on the shoulders of giants.
The journey usually looks something like this:
- Learn a Programming Language: Python is the undisputed king in the AI and machine learning world. Its straightforward syntax and massive ecosystem of libraries make it the perfect place to start.
- Master Key Libraries: Get comfortable with frameworks that do the heavy lifting for you. Industry standards like TensorFlow and PyTorch provide pre-built components, letting you focus on the fun part: designing and training your network, not coding the underlying calculus.
- Start with Simple Projects: Please don't try to build the next ChatGPT on day one! Start with the classics, like a model that can identify handwritten numbers or one that predicts house prices. These projects are perfect for teaching you the fundamental workflow.
- Understand the Training Process: Building the model is just one piece of the puzzle. Knowing how to properly feed it data and guide its learning is where the magic really happens. To get a solid grasp of this cycle, check out our guide on how to train a neural network.
By taking it one step at a time, you'll progressively build up your skills and confidence. You'll go from simple concepts to creating genuinely powerful and useful AI models of your own.





