

Understanding Neural Network Architecture Types
Ever wonder how your phone can pick your face out of a crowd, or how ChatGPT can write a poem that actually rhymes? The magic behind it all is something called a neural network architecture. Think of it as the specific blueprint that dictates how an AI "thinks" and learns.
What Are Neural Network Architectures?
Let's start with a simple analogy. You wouldn't use the blueprint for a skyscraper to build a cozy single-family home, right? They're designed for completely different purposes and need entirely different structures.
It's the exact same in the world of AI. An AI model designed to "see" and interpret images needs a fundamentally different internal wiring than one built to understand the nuances of human language.
This internal structure dictates everything about how information flows through the network, including:
- How many layers, or processing steps, the data goes through.
- What kind of neurons, or mathematical functions, are used in those layers.
- The connection patterns that define how different parts of the network talk to each other.
Getting this design right is arguably the most crucial step in creating an effective AI. The architecture for a self-driving car’s vision system is specialized to find patterns in pixels, whereas the architecture for a chatbot is built to understand sequences and context in words. These aren't just minor tweaks; they are completely different neural network architecture types, each with unique strengths.
Why the Blueprint Is So Important
At its core, the architecture is the AI's strategy for solving a problem. This is a key idea that separates basic machine learning from the sophisticated AI we interact with daily. If you're curious about where that line is drawn, our guide comparing deep learning vs machine learning breaks it down nicely.
When you choose the right blueprint, you give the AI a massive head start. It can learn from data much more efficiently and make far more accurate predictions.
Expert Takeaway: An architecture isn't just a technical detail—it's the embodiment of the problem-solving approach. A well-chosen architecture acts as a strong "inductive bias," giving the model a built-in assumption about the data's structure. This helps it find the right patterns much faster and more reliably.
In this guide, we'll walk through the most important neural network architectures out there. I'll skip the dense academic jargon and use simple, practical examples to explain how each one works, what it's good for, and why picking the right one is the key to building truly intelligent systems.
How AI Learned to See with CNNs
If there's one architecture that gave AI its "eyes," it's the Convolutional Neural Network (CNN). This is the magic behind your phone's uncanny ability to surface every photo of your dog, and it's what allows a self-driving car to distinguish a pedestrian from a lamppost. For practical, real-world applications, CNNs are arguably one of the most impactful neural network architecture types out there.

Imagine you're tackling a massive jigsaw puzzle. You don't try to process the entire mess of pieces at once. You instinctively scan for patterns—a corner piece, a patch of solid blue sky, a snippet of text.
A CNN approaches an image in a surprisingly similar way. Instead of trying to understand the whole picture in one go, it slides a set of digital "filters" across the image to inspect it piece by piece.
The Building Blocks of Digital Vision
Each of these filters is specialized to hunt for a single, specific feature. One filter might be a pro at spotting vertical lines. Another might be tuned to find patches of bright red, while a third looks for gentle curves. It's like having a team of tiny specialists, each with one job.
As these filters move across the image, they create a series of "feature maps"—cheat sheets highlighting where each pattern was found. This process is stacked in layers, building understanding from the ground up:
- Early Layers: These first layers find simple, low-level features like edges, corners, and color gradients. It's like sorting your puzzle pieces into piles of "edge pieces" and "middle pieces."
- Deeper Layers: Taking the simple patterns found by earlier layers, these layers start to combine them into more complex shapes. They learn to recognize an eye by putting together the circles, curves, and shadows identified before.
- Final Layers: At the very end, the network pulls all this information together to identify complete objects. It synthesizes the collections of eyes, noses, and ears to confidently say, "That's a cat."
This step-by-step, feature-building approach is what makes CNNs so powerful for visual data. They learn to see the world much like we do—by assembling simple components into a complex, meaningful whole.
Why CNNs Dominate Visual Tasks
This design isn't just clever; it’s a game-changer. The core idea was introduced way back in the late 80s, but it exploded onto the scene in 2012 when a model called AlexNet blew away the competition at a major image recognition challenge. AlexNet’s success proved that deep CNNs were the definitive path forward for computer vision.
Today, their impact is everywhere:
- Medical Imaging: Spotting tumors in CT scans and identifying anomalies in X-rays. A great real-world example is Google Health's AI, which helps radiologists detect breast cancer more accurately from mammograms.
- Retail: Powering cashier-less stores like Amazon Go, where cameras track what you put in your basket.
- Social Media: Suggesting photo tags for your friends and automatically filtering out inappropriate content.
Expert Opinion: The real brilliance of a CNN lies in its spatial invariance. It doesn't matter if a dog is in the top-left or bottom-right of a picture; the network learns to recognize the features of a dog regardless of where they appear. This makes CNNs incredibly robust and efficient for visual tasks.
The success of CNNs has laid the groundwork for a whole new generation of AI image models. To see just how far things have come, check out our report on Google's upgraded "absolutely bonkers" AI image model. While other architectures certainly have their place, CNNs are still the reigning champions when it comes to seeing and understanding our visual world.
Giving AI a Memory with RNNs
How does your phone’s keyboard guess the next word you’re about to type? And how does a voice assistant follow the thread of a conversation? While CNNs are the eyes of the AI world, Recurrent Neural Networks (RNNs) are its ears and its memory. They are one of the most fundamental neural network architecture types for making sense of sequences.

Think about reading a book. To understand the page you're on, you need to remember what happened in the earlier chapters—who the characters are, their motivations, and the key plot points. RNNs operate on this exact principle. They are built with a feedback loop, which allows information to be carried over from one step in a sequence to the next.
This internal memory, which we call the hidden state, is the magic behind an RNN. As the network processes a sentence word by word or a melody note by note, it continuously updates this hidden state. This means its prediction at any given moment is informed by everything it has processed up to that point.
How RNNs Process Sequential Data
A CNN might look at an entire image all at once, but an RNN takes things one step at a time, in order. At each step, it does two critical things:
- It produces an output. This might be a prediction, like the next word in a sentence. For example, if it has seen "the cat sat on the…", its output might be "mat".
- It updates its hidden state. It merges its memory of the past with the brand-new input, creating a revised memory that it then carries forward to the next step.
This step-by-step processing, combined with that persistent memory, makes RNNs the perfect tool for any task where context and order are king. They're the go-to choice for analyzing time-series data like stock prices, understanding natural language, and building speech recognition systems.
But this simple memory model has a pretty serious flaw.
The Challenge of Vanishing Gradients
The classic RNN, for all its strengths, has a bit of a short-term memory problem. When you feed it a really long sequence—say, a long document or a year's worth of financial data—the information from the very beginning tends to fade away by the time the network gets to the end.
Expert Opinion: This is called the vanishing gradient problem. The influence of early inputs weakens over time, making it incredibly difficult for the network to learn long-range dependencies. It’s like trying to recall the first chapter of a novel when you’re on the last page; the crucial details have become a blur.
This weakness means a standard RNN might fail to connect the subject at the start of a long, complex sentence to the verb at the very end. Finding a solution to AI's memory limitations is a massive area of research. For a deeper dive, you can check out our article on Google's nested learning paradigm that could solve AI's memory problem.
To get around this, researchers developed more sophisticated RNN variants like LSTMs and GRUs. These architectures have special mechanisms called "gates" that give them much better control over what information to remember and what to forget, essentially giving them a more reliable long-term memory.
The Transformer Revolution in Modern AI
If you’ve ever been wowed by a surprisingly human-like chat with ChatGPT or used an AI to summarize a long document, you've witnessed the Transformer architecture in action. While RNNs gave AI a form of memory, Transformers gave it a genuine grasp of context. This model didn't just iterate on old ideas; it completely rewrote the rulebook for understanding language.

Remember how an RNN reads a sentence one word at a time, sequentially? Transformers, on the other hand, can look at the entire sentence all at once. This ability to process in parallel was a massive leap forward, making them far faster and more efficient to train on the enormous datasets modern AI requires.
The Superpower of Self-Attention
The secret sauce that makes Transformers so powerful is a mechanism called self-attention.
Let’s take the sentence: "The delivery truck blocked the street, so it had to turn around." To make sense of this, an AI must figure out that "it" refers to the "truck," not the "street." An RNN, processing one word after another, could easily lose that connection. A Transformer, however, nails it.
Self-attention allows the model to weigh the importance of every single word in relation to all the other words in the sentence. It's like the model can instantly draw lines between related words, highlighting the strongest connections. It learns that in this context, "it" is strongly connected to "truck."
Expert Opinion: The self-attention mechanism is a computational marvel. It creates a rich, contextual map of language, where the model learns not just what individual words mean, but how their meaning shifts depending on the words surrounding them. This is the very foundation for the deep understanding we see in today's large language models (LLMs).
This dynamic ability to map relationships lets Transformers untangle complex grammar, subtle nuances, and long-distance connections that older neural network architecture types always struggled with.
Why Transformers Power Modern LLMs
The combination of parallel processing and self-attention created the perfect recipe for building the massive AI models we see today.
- Scalability: Because Transformers can process entire sequences in one go, they are perfect for training on powerful GPU hardware. This is the key that unlocked our ability to train models with billions, or even trillions, of parameters.
- Contextual Depth: By looking at the whole picture, Transformers build a far deeper and more accurate understanding of the input. This leads directly to more coherent, logical, and useful outputs.
- Versatility: While they made their name in language, Transformer architectures are now showing up everywhere. They're being successfully applied in computer vision (Vision Transformers) and even in complex fields like drug discovery.
This architecture is the direct ancestor of game-changing models like Google's BERT and OpenAI's GPT series. Its arrival marked a clear shift in AI's capabilities—moving from simply processing sequences to truly understanding the intricate web of meaning woven within them.
Digging into Other Creative AI Architectures
Beyond the big three that handle vision and language, the world of AI is brimming with specialized designs. Think of them as custom tools, each crafted for a very specific and often creative job. These neural network architectures push the boundaries of what machines can do, opening up new possibilities in art, data efficiency, and understanding complex relationships.
Let's dive into a few of these more exotic, but incredibly powerful, models.
Generative Adversarial Networks: The Artistic Rivals
Imagine a master art forger and a brilliant detective locked in a high-stakes duel. The forger churns out replicas, while the detective tries to spot the fakes. This is the exact dynamic that powers Generative Adversarial Networks (GANs).
A GAN isn't one network, but two, pitted against each other:
- The Generator: This is our "forger." Its job is to create new, synthetic data—be it an image, a melody, or a paragraph of text—that looks utterly real.
- The Discriminator: This is the "detective." It examines data, both real examples and the generator's fakes, and has to decide if it's looking at the real deal or a counterfeit.
These two are locked in a relentless game of one-upmanship. Every time the discriminator catches a fake, the generator gets feedback and refines its technique. As the forgeries get better, the discriminator is forced to sharpen its senses. This adversarial dance pushes both networks to become incredibly sophisticated. The end result? A generator so skilled it can produce hyper-realistic, entirely new creations. You've probably seen this in action with AI-generated faces of people who don't exist—that's a classic GAN application.
Expert Takeaway: GANs are a beautiful example of unsupervised learning in action. The model learns the deep patterns of a dataset without needing explicit labels. The adversarial process itself creates the learning signal, forcing the generator to master the very essence of the data it's trying to mimic.
First introduced back in 2014, the dual-network design of GANs was a breakthrough for producing synthetic data. The existence of architectures like this shows how the field is constantly evolving, matching model complexity to the unique demands of data and real-world problems. You can learn more about how these neural network components fit together to build such powerful systems.
Autoencoders: The Master Data Compressors
Picture trying to summarize a thousand-page novel into a single, dense paragraph. To succeed, you can't just skim; you have to absorb the core themes and plot, then distill that essence into its most compact form. This is exactly what an Autoencoder does with data.
An Autoencoder has two distinct parts:
- The Encoder: This half takes a large input, like a high-resolution photo, and squeezes it down into a much smaller, condensed representation. This forces the network to learn only the most important features.
- The Decoder: This second half takes that compressed summary and attempts to perfectly reconstruct the original input from it.
The network is judged solely on how well the final output matches the original. To get a good score, the encoder has to become incredibly efficient at capturing the true essence of the data. This unique skill makes Autoencoders fantastic for jobs like anomaly detection.
For example, a bank could train an autoencoder on millions of legitimate credit card transactions. The model gets really good at compressing and reconstructing "normal" spending patterns. When a fraudulent transaction comes along, its pattern is different. The autoencoder struggles to reconstruct it accurately, and the high error rate immediately flags it as a potential problem.
Graph Neural Networks: The Relationship Experts
Not all data fits neatly into a grid of pixels or a straight line of text. What about a social network, a complex molecule, or a city's transit map? These are all graphs—collections of nodes (people, atoms, subway stops) connected by edges (friendships, chemical bonds, train lines).
Graph Neural Networks (GNNs) are built specifically to make sense of these intricate, interconnected webs of data.
A GNN works by passing messages between connected nodes. A node gathers information from its immediate neighbors, learning about its local environment. As the information flows through more layers, each node builds up a sophisticated understanding of its place within the entire graph. This makes them perfect for tasks like recommendation engines (if you're friends with Bob and Carol, and they're both friends with Dave, a GNN might suggest you connect with Dave) or drug discovery (predicting how different molecules might interact).
Choosing the Right AI Architecture for Your Task
With so many neural network architectures out there, it’s easy to feel overwhelmed. But here’s the secret: don't try to memorize every single one. Instead, think like an engineer: what's the problem I'm trying to solve? Different neural network architecture types are really just specialized tools in a toolbox. Your job is to pick the right one for the task at hand.
Let’s work backward from your goal. The nature of your project will almost always point you to the right family of architectures.
Start With Your Problem
Are you trying to make sense of images? Understand human language? Or maybe create something entirely new? Your answer is the most important step.
- Working with Visuals (Images & Video)? If your data is made of pixels, a CNN is almost always your starting point. Its knack for spotting patterns makes it the champ for jobs like image classification, object detection in self-driving cars, or analyzing medical scans.
- Handling Sequences (Text, Speech, Time-Series)? When the order of your data is everything, you need a model with memory. For simpler sequential tasks, RNNs (and their more powerful siblings, LSTMs and GRUs) are a solid choice. But for complex language understanding, Transformers are the current gold standard.
- Generating New Content? If your aim is to create novel and realistic outputs, GANs are a fascinating and powerful option. Their clever adversarial design makes them experts at generating everything from photorealistic faces to original pieces of music.
- Need Efficiency or Anomaly Detection? When you need to boil data down to its core essence or spot outliers, Autoencoders are the perfect tool. They learn what "normal" looks like, making them fantastic for tasks like fraud detection or identifying defective products.
This flowchart gives a great visual for how your core task—whether it's generating new things, compressing information, or analyzing relationships—guides your architectural choice.
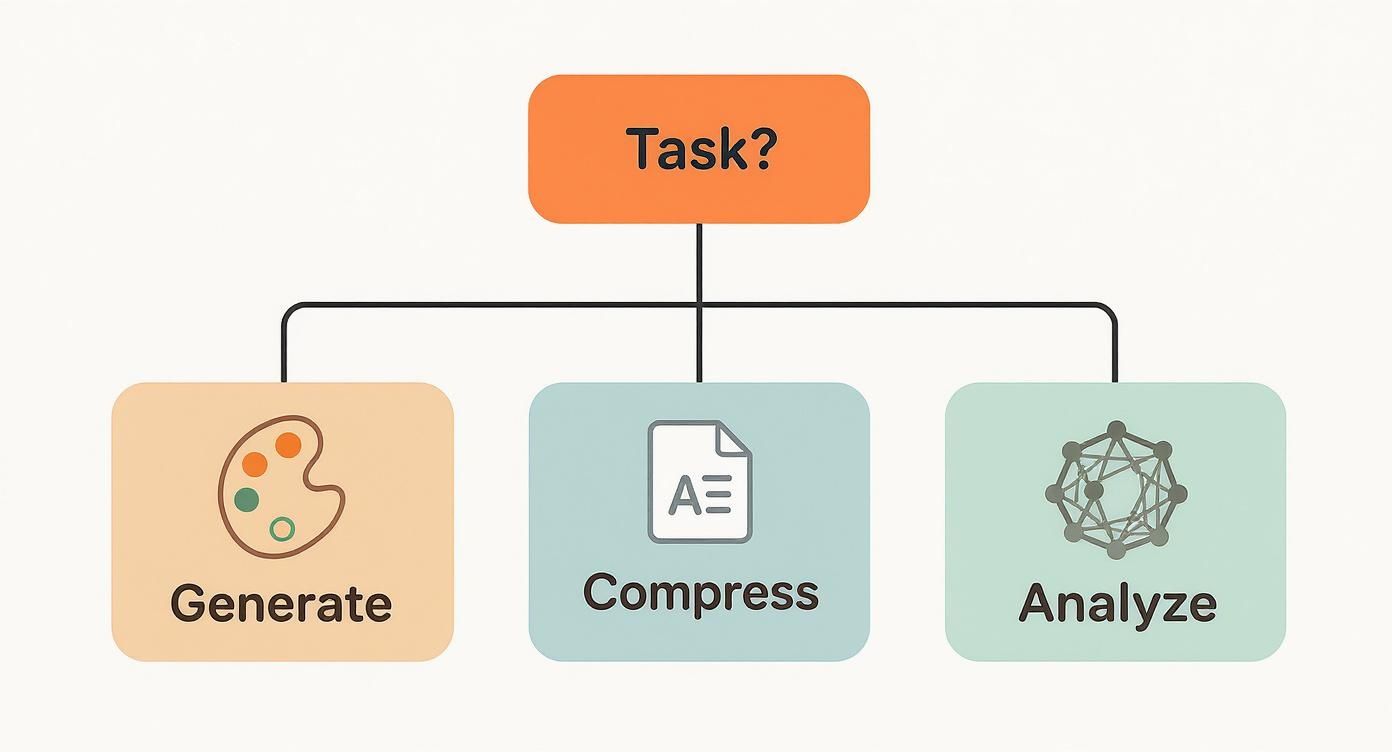
As you can see, the specific goal, whether it's creating art or mapping a social network, maps directly to a specialized AI architecture designed for that very purpose.
A Quick-Reference Guide
To make things even simpler, here's a cheat sheet that connects common problems to their ideal solutions.
Expert Tip: Choosing an architecture isn't about finding the 'best' one in a vacuum. It's about finding the one with the right inductive bias for your problem. A CNN is biased toward finding local patterns in grids (like images), while an RNN is biased to find patterns in sequences. The secret to great results is aligning the model's built-in assumptions with the structure of your data.
Choosing Your Neural Network Architecture
| Architecture Type | Best For… | Key Strength | Example Application |
|---|---|---|---|
| CNN | Images, videos, and grid-like data | Spatial feature detection and hierarchy | Facial recognition in your photo gallery |
| RNN/LSTM/GRU | Sequential data where order is critical | Maintaining a 'memory' of past information | Predicting the next word you type |
| Transformer | Complex language and long sequences | Understanding deep context via self-attention | Powering advanced chatbots like ChatGPT |
| GAN | Generating new, realistic data | Creating highly convincing synthetic outputs | Designing realistic virtual game avatars |
| Autoencoder | Data compression and anomaly detection | Learning an efficient data representation | Spotting fraudulent credit card transactions |
| GNN | Data with complex relationships and networks | Analyzing connections between entities | A social media platform suggesting friends |
By letting your task lead the way, you can cut through the noise and confidently select the perfect foundation from the many neural network architecture types available for your next AI project.
Got Questions About Neural Network Architectures?
Once you start digging into the different types of neural networks, a few questions almost always come up. Let's tackle some of the most common ones to clear things up.
Think of this as a quick debrief to lock in the key ideas we've covered.
Can You Mix and Match Different Architectures?
Absolutely! In fact, some of the most powerful AI systems do exactly this. It’s like assembling a specialist team—you bring in the right expert for each part of the job.
A classic example is an image captioning model. You might see a system that uses:
- A CNN as its "eyes" to process an image and figure out what's happening—identifying objects, actions, and the overall scene.
- An RNN or Transformer as its "voice" to take that visual summary from the CNN and weave it into a natural-sounding sentence, like "A brown dog catches a red frisbee in a park."
This kind of teamwork allows the model to tackle a complex task—seeing and describing—far better than any single architecture could on its own.
So, Which Architecture Is the Best?
This is the classic trick question. There's no single "best" architecture, just like there's no single best tool in a toolbox. You wouldn't use a hammer to cut a piece of wood.
The right choice always comes down to your data and what you’re trying to accomplish. A CNN is king for images. A Transformer is the go-to for understanding language. The goal is to find the architecture that is inherently designed for the shape and patterns of your data.
Expert Takeaway: Let your data lead the way. Don't pick a fancy model and then search for a problem it can solve. Start with your problem and your data, then find the architecture that was built for that exact challenge. That's the secret to building AI that actually works.
Do I Really Need to Be a Math Whiz to Get This?
Not at all! To understand what these architectures do and when to use them at a practical level, you don't need a Ph.D. in mathematics. The analogies we’ve used here—like jigsaw puzzles and art forgers—are often more than enough to give you a solid intuition for making good decisions.
Now, if your goal is to go deeper—to invent new models or fine-tune them for peak performance—then the math becomes much more important. But for navigating the landscape of neural network architecture types and understanding the AI you use every day, a strong conceptual map is the perfect starting point.
At YourAI2Day, we break down complex AI topics into clear, actionable insights. Stay ahead of the curve by exploring our latest articles and guides at https://www.yourai2day.com.





