

How to become a machine learning engineer: A Practical Guide
So, you're interested in building the AI systems that are shaping our world? That's a fantastic goal. Becoming a machine learning engineer is a challenging but incredibly rewarding path, though it's easy to get lost in the sea of online courses and tutorials. This guide is designed to cut through that noise and give you a clear, actionable roadmap, even if you're just starting out and feeling overwhelmed by all the consumer AI hype.
Let's start with a simple truth: a machine learning engineer is, first and foremost, a specialized software engineer. Your job isn't just to understand the theory behind the models; it's to build, deploy, and maintain them in production environments. It's less about poring over academic papers and more about creating robust, scalable systems that solve real business problems.
The Core Pillars of Success
Your journey will stand on three interconnected pillars. Each one you build makes the others stronger.
-
Coding Proficiency: You have to be fluent in a programming language, and for machine learning, Python is the undisputed industry standard. This means going beyond simple scripts. You'll need a deep understanding of essential libraries like NumPy for numerical operations, Pandas for data manipulation, and Scikit-learn for traditional ML models.
-
Mathematical Intuition: No, you don't need a Ph.D. in mathematics. But you absolutely need a solid, intuitive grasp of linear algebra, calculus, and probability. This isn't about memorizing formulas; it's about understanding the logic that makes these algorithms work. It’s the "why" behind the code.
-
Practical Application: Theory is just theory until you apply it. Building a strong portfolio of projects is how you prove you can do the job. This is what separates a promising candidate from a new hire.
Expert Opinion from a Senior ML Engineer: "The biggest trap I see aspiring ML engineers fall into is 'tutorial hell.' They endlessly watch videos and complete guided projects but never venture out on their own. The goal isn't to collect certificates—it's to build things that solve problems. Your first 'real' project, where you have to Google every error message, is where the learning truly begins."
The Journey Visualized
This infographic offers a great high-level view of the process, breaking it down from foundational skills to a career-ready portfolio.
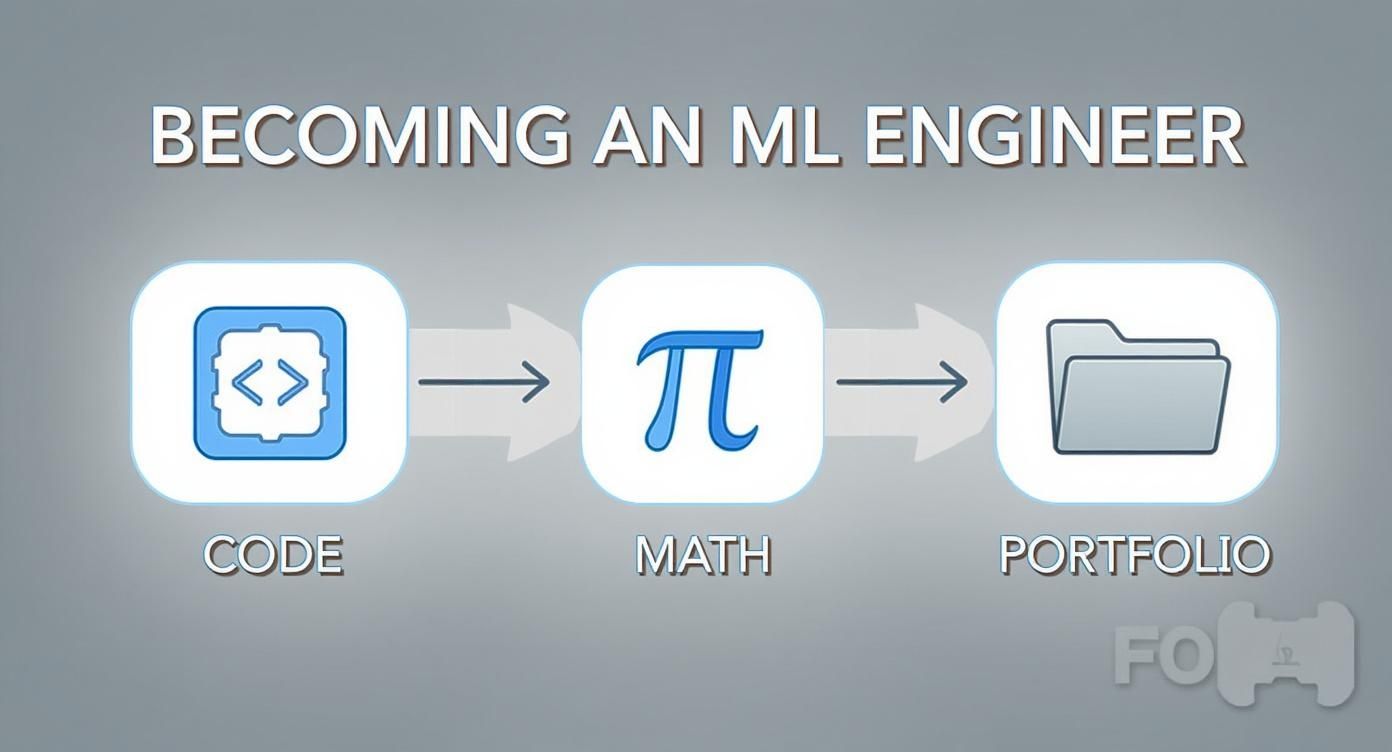
Notice the flow from Code to Math to Portfolio. Each stage builds on the last, turning raw knowledge into tangible proof of your skills. This structured approach is your most direct route into the field. If you're ready to dive in, our guide on how you can learn machine learning is the perfect place to start building your foundation.
Machine Learning Engineer Career Stages At a Glance
To give you a clearer picture of the road ahead, this table breaks down the key stages, from absolute beginner to a specialized professional. It outlines what you should be focusing on, the skills you'll be acquiring, and what success looks like at each step.
| Career Stage | Primary Focus | Key Skills to Acquire | Typical Outcome |
|---|---|---|---|
| Beginner | Building foundational knowledge in code and math. | Python proficiency, core libraries (NumPy, Pandas), linear algebra, calculus, probability theory. | Completion of introductory courses and ability to solve small, guided projects. |
| Intermediate | Applying theory to build end-to-end projects. | Scikit-learn, deep learning frameworks (TensorFlow/PyTorch), data visualization, feature engineering, SQL. | A portfolio with 2-3 unique, self-directed projects showcasing diverse skills. |
| Job Seeker | Refining portfolio and preparing for interviews. | MLOps tools (Docker, Kubernetes), cloud platforms (AWS, GCP, Azure), system design, advanced algorithms, data structures. | A polished GitHub profile, a strong resume, and readiness for technical interviews. |
| Professional | Specializing and solving complex business problems. | Domain-specific knowledge (e.g., NLP, Computer Vision), model optimization, A/B testing, leadership skills. | A successful career with increasing responsibility and impact. |
This progression isn't always linear, but it provides a solid framework for tracking your growth and setting realistic goals for yourself.
The financial incentive for mastering this path is compelling. According to ML engineer salary research from Payscale, the average total compensation for a machine learning engineer in the United States is around $202,331. While entry-level roles might start closer to $96,000, professionals with just 1-4 years of experience often see their earnings climb past $122,000 annually.
Building Your Technical Foundation
Every great structure needs a solid foundation, and your career as a machine learning engineer is no different. We're moving past the high-level ideas now and getting our hands dirty with the essential technical skills you absolutely have to nail down. Think of this as your boot camp before you start building complex AI systems.
We'll start with your most important tool: Python. It’s the undisputed king in the machine learning world for a reason—it’s readable, flexible, and backed by a massive community. Getting truly comfortable with Python is your first real step on this path.
Mastering Python and Its Core Libraries
Learning Python is more than just memorizing syntax for loops and functions. You need to become fluent in the libraries that do the heavy lifting for data manipulation and analysis. These are your new best friends, and you'll be using them every single day.
- NumPy: This is the bedrock for numerical computing in Python. It gives you powerful tools to work with large, multi-dimensional arrays and matrices, which is how computers "see" everything from images to massive datasets.
- Pandas: If data is the new oil, Pandas is your refinery. It provides incredible data structures, like the DataFrame, making it almost trivial to clean, filter, transform, and analyze structured data.
- Scikit-learn: This is your gateway to practical machine learning. It offers a huge collection of tools for everything from preprocessing your data to implementing classic algorithms like linear regression and decision trees right out of the box.
Expert Opinion from a Hiring Manager: "The biggest mistake I see beginners make is jumping to complex models before they've mastered data manipulation. Spend serious time with Pandas. If you can't clean and prepare your data effectively, even the most advanced algorithm in the world will give you garbage results. Show me a project where you handled messy, real-world data, and I'm instantly more impressed than if you just ran a fancy model on a perfectly clean dataset."
To put this into practice, try a mini-project. Go find a public dataset—maybe your city’s public transit data—and use Pandas to answer a simple question. Something like, "Which bus route is most frequently delayed?" This forces you to handle missing values, filter data, and perform calculations, which are the core skills you'll use on every project.
Demystifying the Essential Math
I know the word "math" can be intimidating, but you don't need a Ph.D. in theoretical mathematics. What you do need is a solid intuition for three key areas. This isn't about memorizing formulas; it's about understanding why your models work the way they do.
1. Linear Algebra
This is quite literally the language of data. When you're working with datasets, you're working with vectors and matrices. Understanding concepts like matrix multiplication is non-negotiable because it’s the engine behind neural networks and recommendation systems. When Netflix suggests a show, it’s using linear algebra to calculate similarities between your viewing habits and those of millions of others.
2. Calculus
At its heart, calculus is about understanding change. In machine learning, it's the key to how models "learn." The process of training a model, called gradient descent, uses derivatives (a core concept from calculus) to incrementally tweak the model’s parameters to make better and better predictions.
3. Probability and Statistics
These fields are all about understanding uncertainty and making sense of data. Concepts like probability distributions, p-values, and statistical significance help you evaluate whether your model's predictions are meaningful or just a fluke. They are the tools you use to prove your work is legitimate.
Why Computer Science Fundamentals Matter
Finally, never forget that a machine learning engineer is, first and foremost, a software engineer. Writing code that simply "works" on your laptop isn't good enough. Your code has to be efficient, scalable, and maintainable, especially when it’s running in a live production environment.
This is where your computer science fundamentals come into play.
- Data Structures: Knowing the difference between a list, a dictionary (or hash map), and a set is critical. Using the right data structure can be the difference between code that runs in seconds and code that crashes a server.
- Algorithms: Understanding algorithm complexity (Big O notation) helps you write code that scales. It teaches you to anticipate how your code will perform as the data grows, which is a constant concern in the world of ML.
While a formal degree provides a structured path for these fundamentals, what truly sets you apart is practical skill. Most roles require at least a bachelor's, but the salary data shows a surprisingly small gap between different degrees. For instance, bachelor’s degree holders in ML often earn between $126,144 and $132,883, while those with master's degrees see a modest bump to between $127,037 and $133,843.
This tells us that once you have the foundational knowledge, it's your proven skills and experience that really drive your career forward. You can dig deeper into ML salary trends on Coursera to see just how much experience shapes earning potential.
From Theory to an Impressive Portfolio
Knowing the concepts is one thing, but proving you can apply them is what actually lands you a job. Your project portfolio is the ultimate proof of your abilities, and it’s time to build one that makes recruiters sit up and take notice. Forget rehashing the classic Titanic or Iris dataset tutorials everyone else has on their GitHub; we're going to build something that shows genuine skill and creativity.
Think of your GitHub profile as your new resume. Honestly, it's often the first thing a hiring manager will look at after your application, so we need to make it shine. This means clean, well-documented code and projects that tell a story about how you solve problems.
Your First Project: Getting Your Hands Dirty
Let's start with a foundational project that demonstrates a core competency every single machine learning engineer needs: regression. The goal here isn't to build something groundbreaking. It's to showcase a solid, end-to-end process from start to finish.
A great starting point is predicting housing prices. You can find excellent public datasets for this on platforms like Kaggle. The task is straightforward: predict a continuous value (the price) based on various features like square footage, number of bedrooms, location, and so on.
This project is perfect because it lets you demonstrate several key skills:
- Data Cleaning: Real-world data is messy. You'll have to handle missing values, correct odd inconsistencies, and get the data into a usable format.
- Feature Engineering: This is where you get to be clever. You'll decide which features are important and maybe even create new ones, like a "price per square foot" feature, to help your model perform better.
- Model Training: You can start with a simple model like Linear Regression from Scikit-learn and document your results.
- Evaluation: Show that you can measure your model's accuracy using metrics like Mean Absolute Error (MAE) or R-squared.
The secret sauce here is the documentation. Your GitHub repository for this project absolutely must have a detailed README.md file. Explain your approach, the steps you took, and the conclusions you drew. This is your chance to show a hiring manager how you think.
An Intermediate Project: Adding Complexity
Okay, you've mastered a basic regression task. Time to level up. An excellent intermediate project is building a movie recommendation engine. This moves you from simple tabular data to understanding user behavior and interactions—a challenge that many top tech companies work on every day.
For this, you could use a dataset like the popular MovieLens dataset. This project showcases your ability to work with user-item interaction data, which is a big step up from the housing price predictor.
You'll get to explore concepts like collaborative filtering, a technique that makes recommendations based on what similar users have liked. This demonstrates a deeper understanding of ML algorithms and how they apply to real-world personalization problems. Your goal is to build a system that can take a user's viewing history and suggest new movies they're likely to enjoy.
A Note from Experience: "A recommendation engine is a fantastic portfolio piece because it's immediately relatable. Every hiring manager has used Netflix or Spotify. If you can walk them through how you built your own version, you're demonstrating skills that are directly valuable to a huge number of companies. It's an instant conversation starter."
An Advanced Project: Tackling Unstructured Data
For your advanced project, let's move beyond neat rows and columns and into the world of computer vision. A fantastic project is to build an image classifier to identify different types of plants or animals using a deep learning framework like PyTorch or TensorFlow.
This is where you show you can handle unstructured data (images) and work with more complex models like Convolutional Neural Networks (CNNs). You'll need to find a dataset of labeled images—there are many public ones available for flowers, birds, or even dog breeds.
Your process will involve some seriously cool stuff:
- Data Augmentation: Artificially increasing your dataset size by rotating, flipping, or zooming images to make your model more robust.
- Transfer Learning: Using a pre-trained model (like ResNet) and fine-tuning it for your specific task. This is a crucial, real-world skill that shows you can work efficiently and not reinvent the wheel.
- Deployment: This is the final, most impressive step. Once your model is trained, make it accessible. Build a simple web application using a framework like Flask or FastAPI where a user can upload an image and get a prediction back.
Thinking about how to get your model into the hands of users is a critical part of the job. You can learn more about the fundamentals of machine learning model deployment in our detailed guide, which covers the essential steps for taking your project from a notebook to a live application.
Ultimately, your portfolio should tell a story of your growth. It should show that you started with the fundamentals, tackled more complex problems, and can now handle advanced tasks like deep learning and deployment. A clean, well-documented GitHub with these three types of projects will put you miles ahead of the competition.
Getting to Grips with Core Machine Learning Concepts and Tools
Alright, with your foundations in place, it’s time to get into the heart of what a machine learning engineer actually does. This is where you move beyond general coding and start mastering the specific concepts, algorithms, and tools that bring intelligent systems to life.

First things first, you need to understand the three main ways machines learn. Don't think of these as dense academic theories; they're just different strategies for teaching an algorithm. Getting this right is fundamental because it shapes your entire approach to a problem.
The Three Flavors of Machine Learning
-
Supervised Learning: This is your bread and butter. You have a dataset where the right answers are already known—think of it as a giant answer key. The goal is to train a model to find the connection between the questions (inputs) and the answers (outputs). A perfect real-world example is an email spam filter. It learns from thousands of emails that have already been flagged as "spam" or "not spam" to get good at spotting new junk mail.
-
Unsupervised Learning: What if you don't have an answer key? In unsupervised learning, you give the model a pile of unlabeled data and ask it to find interesting patterns on its own. Imagine an e-commerce company feeding its customer purchase history into a model. The algorithm might discover natural groupings of shoppers—like "coupon clippers," "brand loyalists," or "late-night buyers"—without any prior hints.
-
Reinforcement Learning: This is all about learning from trial and error. You build an "agent" that interacts with an environment, receiving rewards for good actions and penalties for bad ones. Think of training an AI to play Pac-Man. It learns the best route by getting points (a reward) for eating pellets and getting punished (losing a life) when it runs into a ghost.
Most of your early projects will probably fall under supervised learning. It's incredibly versatile and solves a massive number of business problems, from predicting house prices to identifying credit card fraud.
Your Go-To Algorithms
Once you know the type of learning you need, you have to pick the right tool for the job—an algorithm. While there are hundreds out there, a small handful of workhorses will solve the vast majority of problems you'll encounter.
A decision tree, for example, works like a simple flowchart. It asks a series of yes/no questions to arrive at a conclusion. They're fantastic because you can literally see the logic the model learned, making them super easy to explain. You could use one to build a basic loan approval model that asks things like, "Is their income over $50,000?" and "Is their credit score above 650?"
Then you have something like logistic regression. Despite the name, it’s used for classification—predicting a category. It’s a go-to for any "yes or no" question, like figuring out if a customer is likely to cancel their subscription. It calculates the probability of an outcome, making it both reliable and efficient.
Choosing Your Deep Learning Framework
When your projects get more complex—think image recognition or understanding human language—you'll need the heavy hitters: deep learning frameworks. The two giants in this arena are TensorFlow and PyTorch.
Honestly, the debate over which is "better" is mostly noise. Both are incredibly powerful, and once you know one, picking up the other is a breeze. The most important thing is to just choose one and get really good at it.
A lot of beginners find PyTorch's syntax to be more intuitive and "Pythonic," which can make it a smoother starting point. TensorFlow, backed by Google, has a massive ecosystem and tools like TensorFlow Serving that make it a beast for large-scale production systems.
To help you decide, here's a quick rundown of how they stack up for someone just starting out.
TensorFlow vs PyTorch: A Quick Comparison for Beginners
| Feature | TensorFlow | PyTorch |
|---|---|---|
| Learning Curve | Can be steeper for beginners due to its more extensive API and concepts. | Generally considered more intuitive and easier to learn for Python developers. |
| Production Deployment | Excellent production-ready tools like TensorFlow Serving and TFX. | Has strong deployment options with TorchServe, but historically TF had an edge. |
| Community & Ecosystem | Massive community and a mature ecosystem with many pre-built models. | Rapidly growing community, especially popular in academic research. |
| Debugging | Uses a static computation graph, which can make debugging less direct. | Employs a dynamic graph, allowing for more straightforward, Pythonic debugging. |
Ultimately, you can't go wrong with either. If you want a more in-depth analysis, our guide on the most popular machine learning frameworks explores the nuances to help you make the right call for your goals.
MLOps: The Skill That Actually Gets You Hired
Here’s a piece of advice I wish I had taken seriously from day one: MLOps is not optional anymore. MLOps (Machine Learning Operations) is the art and science of getting your models out of a messy notebook and into the real world where they can run reliably and at scale.
Expert Opinion from a Staff Engineer: "A model that only works on your laptop is just a science experiment. A model that runs in production and provides value to users is what a machine learning engineer builds. This shift in mindset is crucial for your career. Can you containerize it? Can you deploy it? Can you monitor it? These are the questions that get you hired."
This means you need to get comfortable with tools that might not seem like "core ML" at first glance.
- Docker: This lets you package your code, libraries, and all their dependencies into a self-contained "container." It solves the eternal "it worked on my machine" problem by ensuring your model runs the exact same way everywhere, from your laptop to a cloud server.
- Cloud Platforms (AWS, GCP, Azure): You have to know how to use the cloud. It's where you'll train models on powerful hardware you could never afford and deploy them to handle thousands of requests per second. Learning the basics of a service like Amazon S3 for storage or EC2 for computing is a massive resume booster.
Navigating the Job Hunt and Acing the Interview
You’ve done the work. You’ve built the skills, and you have a portfolio of projects to prove it. Now it’s time for the final push: landing the job. This is where your technical abilities have to shine alongside your communication, strategy, and even a bit of psychology. Let's build a playbook for navigating the machine learning job market and nailing those interviews.
Your first challenge isn’t a person—it’s a piece of software. Most companies rely on an Applicant Tracking System (ATS) to sift through resumes before a human ever lays eyes on them. To get past this digital gatekeeper, your resume needs to be clean, well-structured, and loaded with the right keywords pulled directly from the job description.
But outsmarting the bot is only the first step. You still have to catch the eye of a human recruiter. The single best way to do this is by quantifying your achievements. Don't just say you "built a recommendation engine." Instead, frame it with impact: "Developed a movie recommendation engine using collaborative filtering that improved user engagement metrics by 15% in a test environment." Numbers tell a compelling story.
Cracking the Multi-Stage Interview Process
Once your resume lands on the right desk, get ready for a multi-stage process. This isn't just one conversation; it's a series of hurdles designed to evaluate you from every possible angle. While the specifics can vary, the overall structure is remarkably consistent across the industry.
Here’s a typical interview loop you can expect to encounter:
- The Technical Screen: This is usually your first real test—a coding challenge. Expect questions centered on Python fundamentals, classic data structures, and algorithms. They need to see that you can write clean, efficient code before they invest more time in you.
- The ML Theory Deep Dive: Next, they'll probe your foundational knowledge. An interviewer might ask, "Can you explain the bias-variance tradeoff in your own words?" or "When would you choose a Random Forest over a Gradient Boosting model?" Be ready to move beyond textbook definitions and discuss the real-world implications of your choices.
- The System Design Round: This is often the most intimidating stage, especially for junior engineers. The questions are intentionally broad and open-ended, designed to see how you solve problems, not just if you know a specific answer.
- The Behavioral Chat: Whatever you do, don't underestimate this stage! They want to know if you're a good teammate and how you handle pressure. Be prepared for questions like, "Tell me about a time a project failed," or "How do you handle technical disagreements with colleagues?"
A Note from the Trenches: The system design interview isn't about finding the one 'right' answer, because one rarely exists. It's a performance. The interviewer wants to see you ask clarifying questions, state your assumptions out loud, and break down a massive, messy problem into manageable chunks. Your thought process is what's being graded, not the final diagram.
Answering the System Design Question
Let's walk through a classic system design question: "How would you build a fraud detection system for online transactions?" It's easy to freeze up, but having a simple framework in your back pocket can make all the difference.
- Clarify and Scope: Immediately start asking questions. What kind of transactions? What data do we have access to? What's the latency requirement—are we blocking transactions in real-time or just flagging them for review later? Nailing down the constraints is half the battle.
- Sketch the Data Flow: Think high-level first. You’ll need a way to ingest transaction data (maybe from a message queue like Kafka), a feature engineering pipeline, a model to make predictions, and a way to store and serve those results. Draw it out on the whiteboard.
- Talk Through the Model: Now, you can zoom in on the model itself. You could suggest starting with a simple, fast model like Logistic Regression for a baseline and then exploring more complex options like a Gradient Boosting Machine (XGBoost) if needed. Crucially, mention how you'd handle the imbalanced data—fraud is rare, which is a classic ML problem.
- Think About Production: This is what separates a good answer from a great one. How will you monitor the model for performance drift? How often will you retrain it with new data? Mentioning MLOps concepts shows you’re thinking like an engineer who has to maintain this system, not just a data scientist who built a one-off model.
Where You Live Matters
Finally, you have to be realistic about the job market, and a huge part of that is geography. Where you work has a dramatic impact on both the number of opportunities and your potential salary.
Compensation for machine learning engineers varies wildly, with major tech hubs offering a significant premium. For example, San Francisco offers an average of around $193,919 annually, while Austin, Texas, is competitive at $207,775. New York City often leads the pack, with salaries reaching $226,857 or more—that's a premium of over 40% above the U.S. national average. For many aspiring engineers, being open to relocation can mean a substantial increase in earning potential. You can dive deeper into AI salary trends across the U.S. to see how different markets really stack up.
Your Machine Learning Career Questions Answered

The path to becoming a machine learning engineer is exciting, but it definitely comes with its share of questions. Let's dig into some of the most common ones I hear, so you can move forward with a clear head.
How Long Does This Journey Take?
There's no single answer here, but if you're already comfortable with programming, a realistic timeline is anywhere from 1-3 years.
This typically breaks down into about 6-12 months of dedicated learning—getting the theory and tools down—and another 6-12 months of serious project work to build a portfolio that actually stands out.
Coming in with zero coding experience? Plan on adding about a year to that estimate. You'll need that time to build a solid software engineering foundation first. The key is consistency; this is a marathon, not a sprint.
Do I Really Need a Masters or PhD?
For a pure engineering role, usually not. While a PhD is often table stakes for research-heavy ML Scientist positions, most ML Engineer jobs are far more interested in your practical coding skills and your project portfolio. A Bachelor's degree in a STEM field is generally enough if you can demonstrate you know your stuff through tangible work.
Expert Take: "That said, in a crowded job market, a Master's can be a significant advantage. It's not a hard requirement, but think of it as a powerful tie-breaker when you're up against another strong candidate with a similar portfolio. It signals a level of formal, structured learning that some hiring managers still value."
What Are the Biggest Mistakes Beginners Make?
It’s easy to get tripped up when you're starting out. I’ve seen countless junior engineers—and talked to plenty of hiring managers—and a few common pitfalls always surface.
Here are the top three mistakes to actively avoid:
- Getting stuck in "tutorial hell." This is probably the biggest one. You can follow courses and collect certificates all day, but that doesn't make you an engineer. The real learning happens when you break away and start building something entirely on your own, from scratch.
- Skipping the fundamentals. Everyone wants to jump right into building fancy deep learning models. It's a classic mistake. You absolutely have to master the less glamorous, but critical, basics first: data cleaning, feature engineering, and classic algorithms like logistic regression. This is the bedrock of everything else.
- Neglecting software engineering skills. Remember, an ML Engineer is a software engineer first, and an ML specialist second. You must write clean, maintainable code. You have to be proficient with version control (Git). And you need to understand core system design principles. These are not optional extras; they're the core of the job.
Steering clear of these traps will make your journey into this field much smoother and, ultimately, more successful.
At YourAI2Day, we're dedicated to bringing you the clearest and most practical insights into the world of AI. For more guides, news, and tools, check out our resources at https://www.yourai2day.com.





