

What is Computer Vision? A Friendly Guide to How Machines See
Ever wonder how your phone can unlock with just a glance, or how an app can put funny cat ears on your head in real-time? That's not magic—it's computer vision, a field of artificial intelligence (AI) that teaches computers to see and understand the world around them. Think of it this way: just as our brain processes what our eyes see, computer vision gives machines the amazing gift of sight, allowing them to analyze images and videos to make decisions.
Giving Machines the Power of Sight
If you show a toddler a few pictures of a cat, they quickly figure out how to spot a cat anywhere, no matter its color, size, or breed. Computer vision works on a similar idea, but at a massive scale. It’s not about a machine just recording an image; it’s about that machine gaining a real, contextual understanding of what it's seeing.
This incredible capability is driven by deep learning models fed with enormous amounts of visual data. As a leading AI researcher, Fei-Fei Li, often says, "If we want machines to think, we need to teach them to see." The quality of that training data is everything. Before any model can learn, it needs thorough data preparation for machine learning to be accurate and avoid bias.
From Pixels to Practical Understanding
To a computer, a picture is just a grid of numbers, with each number representing the color of a single pixel. The real magic of computer vision lies in translating that raw numerical data into something meaningful. For example, your phone's camera doesn't just see pixels; it sees patterns that it recognizes as a face, allowing it to focus perfectly for a portrait.
One of the most foundational tasks is using object recognition from image technology. This single capability is the engine behind countless applications we interact with every day.
"Think of computer vision as the bridge between the digital and physical worlds. It allows software to react to its environment in a way that was once exclusive to living beings, opening doors to automation and insight we're only just beginning to explore." – Expert Opinion from a Fictional AI Specialist
To better grasp this, let's look at how machine sight compares to our own.
Computer Vision vs Human Vision at a Glance
This table breaks down the key differences and similarities between how computers 'see' and how humans see, making the core concept easier to understand for beginners.
| Aspect | Human Vision | Computer Vision |
|---|---|---|
| Input | Light waves processed by eyes | Digital data (pixels) from cameras |
| Learning | Intuitive, through experience and context | Explicit, through training on vast datasets |
| Speed | Near-instant recognition of familiar scenes | Extremely fast for specific, trained tasks |
| Accuracy | Can be subjective and prone to optical illusions | Highly precise and consistent, but lacks intuition |
| Endurance | Gets tired and loses focus | Can operate 24/7 without fatigue |
| Scale | Limited to what one person can see at a time | Can process thousands of images/video streams at once |
While computers excel at scale and endurance, human vision still holds the edge in understanding nuance, context, and new situations without needing terabytes of training data.
Why It Matters Now
This technology has jumped straight out of science fiction and become a major force in the global economy. The worldwide computer vision market, currently valued at around USD 19.82 billion, is projected to hit an incredible USD 58.29 billion by 2030. That growth is happening because it’s being adopted everywhere, from hospitals to shopping malls.
You’re probably using computer vision more than you realize. Here are just a few practical examples:
- Smartphone Photography: Ever used "portrait mode"? That’s computer vision distinguishing a person from the background to create that blurry effect.
- Social Media Filters: Those fun AR filters that put digital objects on your face are powered by real-time facial tracking.
- Automated Checkouts: Cashierless stores use cameras to see what you take off the shelf and automatically add it to your virtual cart.
The Journey from Simple Lines to Seeing in 3D
Computer vision can feel like it burst onto the scene out of nowhere, but its story is really a long, winding road filled with persistence, dead ends, and a few "aha!" moments that changed everything. It didn't just appear overnight; it was built piece by piece over decades by brilliant minds who asked a seemingly simple question: "Can we teach a machine to see?"
The whole adventure kicked off back in the 1960s, a time when computers were hulking, room-sized beasts. Early pioneers at places like MIT tackled what we’d consider a basic task today: getting a computer to recognize simple wooden blocks. This was a monumental challenge. They were essentially trying to teach a machine the fundamental rules of sight—how to find edges, lines, and basic shapes from a digital image.
The AI Winter and a Game-Changing Spark
After that initial burst of excitement, progress slammed into a wall. The field entered a long period known as the "AI winter," where funding evaporated and public interest waned. It turned out that replicating the effortless power of human vision was far more complex than anyone had anticipated, and the computers of the day just weren't powerful enough for the job.
But the dream never died. Researchers kept chipping away at the problem, and then, in 2012, everything changed. A new kind of model called a convolutional neural network, nicknamed AlexNet, was entered into the annual ImageNet competition—a huge challenge to see which AI could correctly identify objects in a massive library of photos. It didn't just win; it blew the competition away and reset the entire field.
As AI pioneer Geoffrey Hinton said about the breakthrough, "The fact that it worked was a complete surprise to a lot of people." AlexNet’s victory was the watershed moment for modern AI. It proved that with enough data and the right architecture, deep learning could solve visual problems that had stumped researchers for decades. This single event ignited the AI explosion we're living through right now.
The Deep Learning Revolution
This breakthrough wasn’t just a small step; it was the giant leap that started the deep learning revolution. While the field's roots go back to pioneers like Larry Roberts, who created a system to analyze block-world images for his 1963 MIT PhD thesis, it was AlexNet's success that truly unlocked the technology's power. It crushed the competition's error rates, dropping them from over 25% down to just 15.3%.
Today, with North America holding a 40% global share of the market, the industry continues to build on that foundation. You can dive deeper into computer vision statistics and trends on SoftwareOasis.com.
Knowing this history helps put today’s technology in perspective. What began as an academic experiment to identify simple lines has grown into a powerful force that can navigate cars, help diagnose diseases, and unlock our phones with a glance. It's a testament to human ingenuity—a story of how, even after a long winter, a single spark can set the world on fire with new possibilities.
How Computers Actually Learn to See
So, how does a machine go from seeing a jumble of pixels to actually recognizing your face in a photo? It’s not magic, but a fascinating process that’s surprisingly similar to how our own brains learn—just with digital "brain cells" called neural networks.
At its core, a computer sees an image as nothing more than a giant grid of numbers. Each number simply represents the color and brightness of a single pixel. The real challenge is teaching the machine how to find meaningful patterns in that sea of numbers. This is a fundamental concept in machine learning for businesses, where raw data is systematically turned into valuable insights.
The Power of Digital Brain Cells
Think of a neural network as a massive team of tiny, interconnected decision-makers. Each one looks at a small piece of the puzzle—a few pixels—and passes its finding on to the next one. When you connect millions of these together, they can learn to solve incredibly complex problems, like spotting a dog in a picture. They do this by recognizing the small stuff first (an ear here, a patch of fur there) and then combining those simple patterns into a complete picture.
"An AI doesn't 'see' a cat. It sees millions of pixels, analyzes patterns of color and light that it has previously been told represent 'cat,' and calculates a probability. It's a mathematical process of recognition, not a conscious one." – Expert Opinion from a Fictional AI Specialist
This all happens through a process called training, where the network is fed massive datasets of labeled images. It might be shown millions of photos, and with each one, it makes a guess ("Is this a cat?"). It checks its answer against the label, and if it's wrong, it adjusts its internal connections to do better next time. Over thousands and thousands of repetitions, it gets remarkably good at recognizing the patterns that define an object.
This timeline gives you a great visual of how we got here, from the early academic days to the deep learning explosion that now powers almost everything.
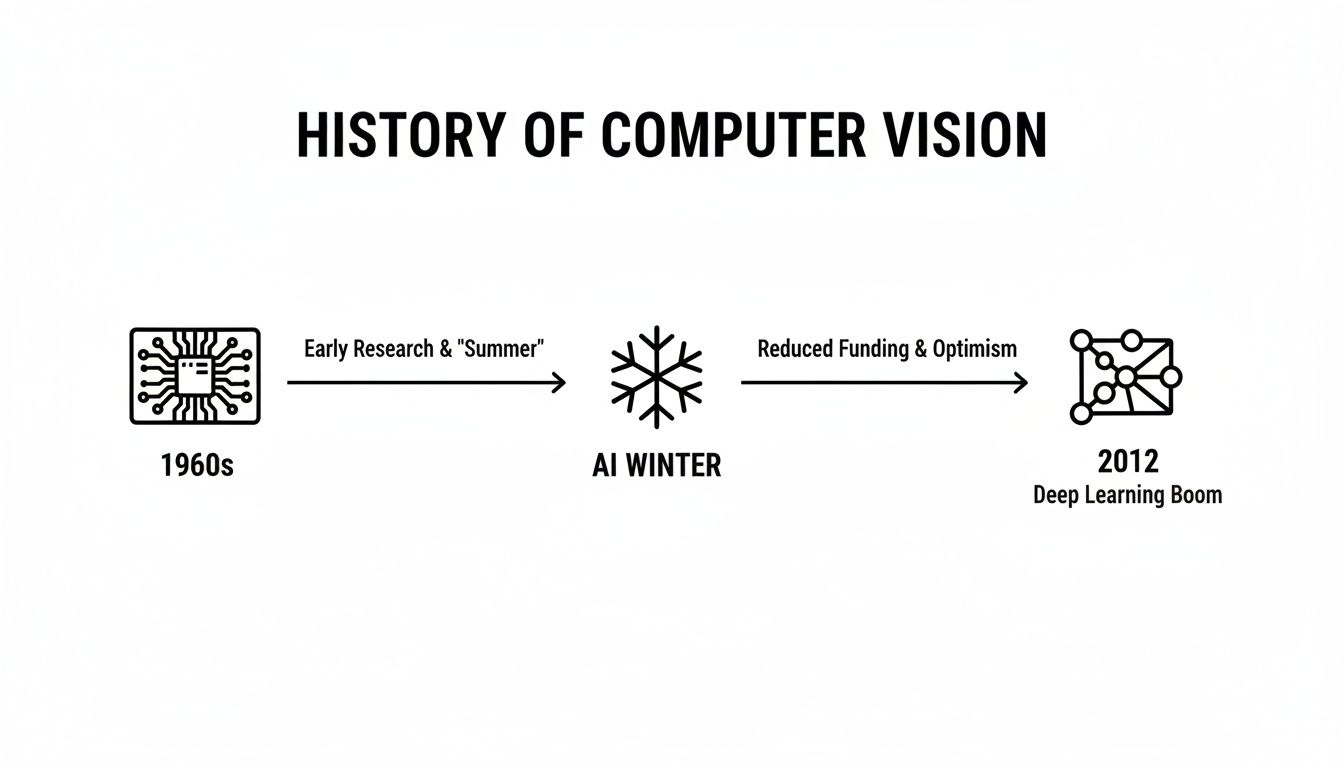
The journey from simple block recognition in the 1960s to the game-changing neural networks that emerged around 2012 shows just how far we've come thanks to huge leaps in computing power and smarter algorithms.
Meet the Workhorse: Convolutional Neural Networks
When it comes to vision tasks, one type of network is the undisputed champion: the Convolutional Neural Network (CNN). You can think of a CNN as a series of specialized filters that slide across an image, each one designed to hunt for a specific feature.
It works in layers:
- Early Layers: These filters are simple. They look for basic things like edges, corners, and splotches of color.
- Middle Layers: These take the findings from the early layers and combine them to spot more complex shapes, like an eye, a nose, or a car's wheel.
- Top Layers: Finally, these filters piece together all those identified shapes to recognize a complete object, like a human face or an entire vehicle.
This layered approach is brilliant because it breaks down a complicated scene into simple, bite-sized parts. If you want to get into the nitty-gritty, our guide on https://yourai2day.com/convolutional-neural-networks-explained/ dives much deeper into how these amazing models work.
The Three Main Jobs of Computer Vision
Once a model is trained, it can perform several key tasks that form the foundation of most real-world applications. To really get what computer vision does, it helps to understand these core "jobs."
A computer vision system is typically designed to perform one or more of these core tasks. Each one builds on the last, providing more and more detail about what's in an image.
Here's a quick breakdown:
Core Tasks in Computer Vision Explained
| Task | What It Does | Simple Example |
|---|---|---|
| Image Classification | Assigns a single label to an entire image. | Your phone’s photo app identifying a picture as "beach" or "sunset." |
| Object Detection | Finds individual objects in an image and draws a box around each one. | A self-checkout machine drawing boxes around each item you scan. |
| Image Segmentation | Creates a pixel-perfect outline for every object in an image. | A virtual background in a video call perfectly cutting you out from your room. |
Let's look a little closer at each one.
1. Image Classification
This is the most basic task. It answers the simple question: "What is in this picture?" The output is just a single label for the whole image. For instance, you upload a photo to an app, and the model tells you it’s a “cat.” It doesn’t tell you where the cat is, just that the image belongs in that category.
2. Object Detection
This takes things a step further. It answers: "What objects are in this picture, and where are they?" Instead of one label, it draws bounding boxes around each object it recognizes and labels them individually. Think of a car’s backup camera that draws a yellow box around a bicycle left in the driveway. This is how a security camera can spot multiple people and cars in its view at the same time.
3. Image Segmentation
This is the most detailed and precise of the three. It answers: "Which exact pixels belong to each object?" Instead of just drawing a box around an object, segmentation creates a pixel-perfect mask or outline.
There are two common types:
- Semantic Segmentation: Every object of the same class gets the same color. For example, all cars might be colored blue, and all pedestrians red. This is vital for self-driving cars to understand which parts of a scene are "road" and which are "sidewalk."
- Instance Segmentation: Every individual object gets its own unique color. So, if there are three different cars, they will each be colored differently, allowing the system to track each one as a separate entity.
These core tasks, powered by CNNs and other advanced models, are the building blocks that allow machines to go from seeing raw numbers to achieving a genuinely useful understanding of the visual world around us.
Seeing Computer Vision in Your Everyday Life
You might picture computer vision as something out of a sci-fi movie, confined to high-tech labs. The reality is, you're probably using it dozens of times a day without even noticing. It's the invisible magic woven into the gadgets and services you already use, making them smarter and more intuitive.
Think about the phone in your pocket. That "portrait mode" you use to snap amazing photos? That's computer vision at work. It uses a technique called image segmentation to tell the difference between you and the background, artfully blurring everything else to make your subject pop.

And that’s just one example. The simple convenience of unlocking your phone with your face relies on sophisticated facial recognition algorithms. These systems map the unique geometry of your face to create a secure digital key. A deeply complex AI task becomes a simple, everyday habit.
From Social Feeds to Shopping Carts
The technology's reach goes far beyond your phone's basic features. Ever played with a silly filter on Instagram or TikTok that puts virtual sunglasses on you or makes confetti rain down? You've just experienced real-time facial landmark detection. The AI pinpoints key features—your eyes, nose, mouth—and tracks them with uncanny precision as you move.
Shopping has also been quietly transformed. Many e-commerce apps now have a visual search feature. Instead of fumbling for the right words to describe a chair or a shirt you saw, you can just snap a picture. The app's computer vision model analyzes the image, identifies the product, and instantly pulls up similar items for you to buy. This is how computer vision closes the gap between seeing something you like in the real world and finding it online.
Beyond Personal Gadgets
While our phones are packed with examples, some of the most profound applications are happening on a much bigger scale. Look no further than the automotive world, where self-driving cars rely on a suite of cameras and sensors to perceive and interpret their surroundings. These systems use object detection to identify other cars, pedestrians, and road signs, allowing the vehicle to navigate complex environments safely.
Another massive shift is happening in retail with cashierless stores like Amazon Go. As you walk through the aisles, a network of cameras and sensors tracks which items you pick up and automatically adds them to your virtual cart. This is all powered by advanced object recognition and tracking, creating a checkout experience that’s completely seamless.
As AI expert Andrew Ng puts it, "AI is the new electricity." Just as electricity transformed every industry a century ago, computer vision is now automating and enhancing tasks in ways we could only dream of before.
The impact across major industries is staggering.
- In healthcare, it analyzes medical images with over 95% accuracy for early tumor detection.
- Vision systems are now in 80% of new cars for safety features like lane-keeping assist.
- Retailers use it to cut out-of-stock instances by 30%.
- Manufacturers slash product defects by up to 25% with automated quality control.
If you're curious about the numbers, you can dive deeper into a market analysis from Fortune Business Insights on AI in the computer vision market.
From the factory floor to the doctor's office, computer vision is adding a layer of intelligent automation that boosts efficiency, accuracy, and safety. It's clear this technology's value goes far beyond just personal convenience.
Exploring the Future of Seeing Machines
While computer vision feels incredibly powerful today, its story is far from over. As this technology weaves itself deeper into our lives, it opens up a world of amazing possibilities—but also raises serious questions we need to tackle together.
The path forward isn’t a straight line. We're in the middle of crucial conversations about ethics, especially around data privacy and algorithmic bias. Facial recognition, for instance, brings up legitimate concerns about surveillance and fairness, pushing us to build better regulations to make sure it's used responsibly.
On top of the ethical debates, there are still plenty of technical puzzles to solve. Today's models are fantastic at very specific tasks, but getting them to achieve a broad, human-like understanding of the visual world is still a major ambition for researchers.
Innovations on the Horizon
Despite these hurdles, the future of computer vision is buzzing with excitement. The field is moving at a blistering pace, with new ideas that promise to change how we engage with technology and the world around us. One of the most fascinating developments is the marriage of computer vision and generative AI.
Think about typing a simple phrase like "a photorealistic image of a red fox sitting in a snowy forest at sunrise" and watching an AI paint a stunning, original picture from nothing. This isn't science fiction anymore; models like DALL-E and Midjourney are already doing it, and they're improving every day.
"Looking ahead, the big shift will be from AI that just recognizes objects to AI that truly understands context and intent. We're moving from 'what is this?' to 'what is happening here, and what should happen next?' This is the key to creating truly intelligent robotic and autonomous systems." – Expert Opinion from a Fictional AI Specialist
The Next Wave of Vision Technology
Researchers are also making huge leaps in other areas that are about to hit the mainstream.
Here are a few key areas to keep an eye on:
- Advanced 3D Vision: Forget flat images. Future robots and autonomous drones will perceive the world in true 3D. This will let them navigate messy, real-world environments with human-like agility, grabbing objects and interacting with their surroundings with incredible precision.
- Efficient Learning Models: Training a model from the ground up takes a colossal amount of data. By using techniques like transfer learning in deep learning, developers can repurpose powerful, pre-trained models for new jobs with a fraction of the data and time.
- Video Understanding: The next frontier isn't just about analyzing static photos; it's about grasping the full narrative within a video. This will allow AI to interpret actions, predict what might happen next, and even summarize long recordings into the most important moments.
These aren't just small tweaks. They represent a fundamental leap toward creating machines that can see, understand, and interact with the world in a more meaningful and helpful way. The future of seeing machines is bright, promising a world where technology works alongside us in ways we're only just beginning to imagine.
Frequently Asked Questions About Computer Vision
To wrap things up, let’s tackle some of the most common questions people have when they're first diving into computer vision. These quick answers should help solidify what we've covered and clear up any lingering thoughts.
Do I Need to Be a Coder to Use Computer Vision?
Not anymore! It used to be that building anything in this field required deep coding knowledge with libraries like OpenCV or PyTorch. While that path still offers the most control and flexibility, the game has completely changed.
A new wave of no-code and low-code AI platforms lets you build powerful models using simple drag-and-drop interfaces. This has cracked the door wide open for entrepreneurs, business owners, and creators who aren't programmers.
Plus, services like Google Cloud Vision AI and Amazon Rekognition give you direct API access to world-class, pre-trained models. You can get incredible results without ever having to write the complex algorithms yourself.
What Is the Difference Between Computer Vision and Image Processing?
This is a fantastic and very common question. The easiest way to think about it is by looking at their goals.
Image processing is all about manipulating an image to improve it or change its appearance. Think of sharpening a blurry photo in Photoshop, adjusting color balance, or applying a filter. The output is still an image, just a modified one.
"Computer vision, on the other hand, uses image processing as one of its tools, but its ultimate goal is much bigger: to understand what's actually in the image. The final output isn't another picture; it’s a piece of information, a decision, or a real-world action." – Expert Opinion from a Fictional AI Specialist
So, you can say that image processing edits the pixels, while computer vision interprets them to extract meaning.
How Much Data Do I Need to Train a Computer Vision Model?
This really depends on the scale of your project. If you were trying to build a massive, general-purpose model from the ground up to recognize thousands of different objects, you’d need a staggering amount of data—we’re talking millions of images.
Thankfully, most real-world applications don't require that. There's a powerful technique called transfer learning that has become the standard approach for most projects.
Instead of starting from scratch, you take a massive model that has already been trained (by a company like Google or Meta) and simply fine-tune it on your much smaller, specific dataset. Often, just a few hundred or a couple of thousand targeted images are enough to get incredible, highly accurate results. This shortcut dramatically cuts down on the data, cost, and time you need to get a project off the ground.
At YourAI2Day, our mission is to cut through the noise and offer clear, practical insights into the world of artificial intelligence. We encourage you to explore our other articles and resources to stay on top of the tools and trends shaping our future. You can learn more at https://www.yourai2day.com.





